Performance Optimisation and Productivity
Align branch granularity to warps
Pattern addressed: GPU branch divergenceThis pattern applies to GPU computing, where the execution of a thread block is divided into warps with a constant number of threads per warp. When threads in the same warp follow different paths of control flow, these threads diverge in their execution, which serializes the execution. (more...)
To mitigate the problem of GPU branch divergence it is recommended to align the branch granularity to the warp size.
The following figure shows the effect of aligning the branch granularity:
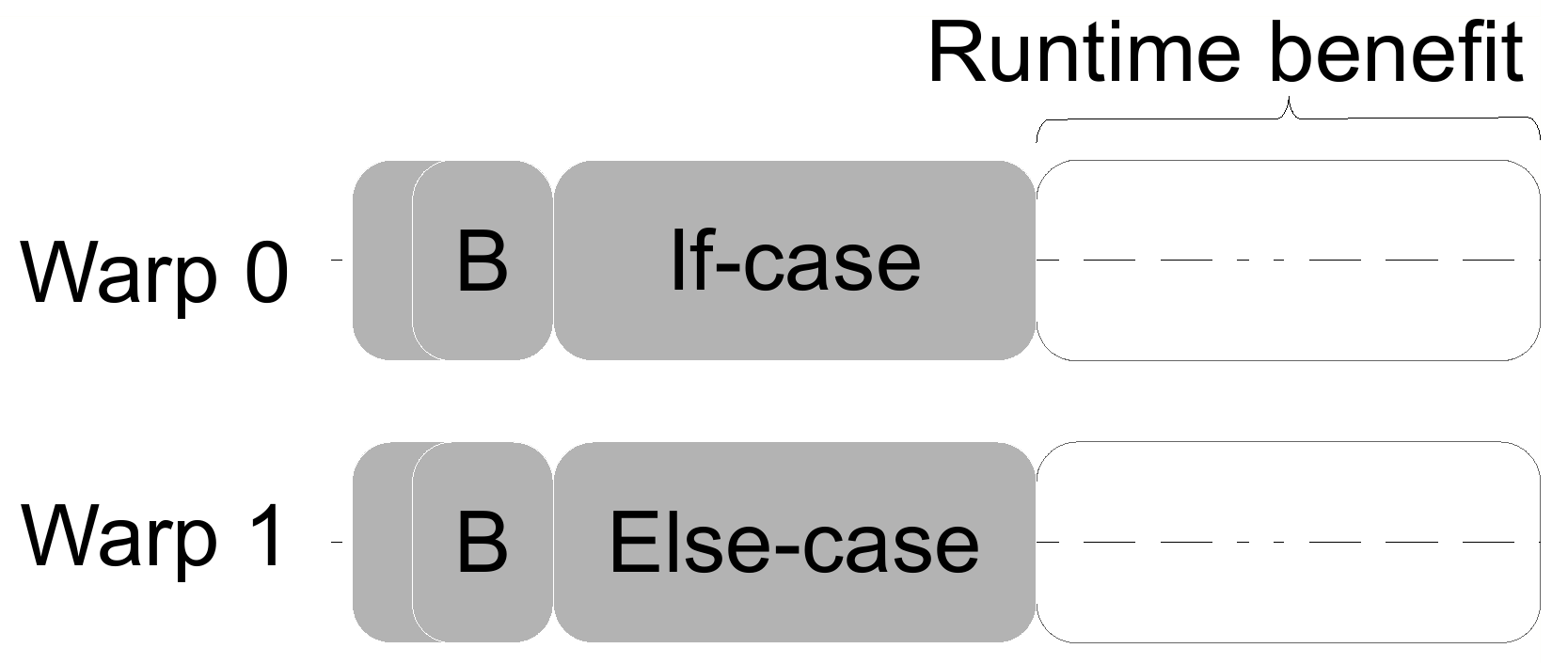
This might be done manually for simple kernels, however, achieving alignment for complex kernels is not a simple task. Multiple methods have been proposed to reduce the performance penalty caused by branch divergence, we discuss two of those, iteration delaying and branch distribution.
Iteration delaying
Iteration delaying is a run-time optimization technique that targets the if-else scenario if there’s a loop enclosing the branch condition. The main idea is that, in each loop iteration, instead of all warp threads going through both paths of the branch, they all take one of the paths. Those that should take the other
path simply do nothing, delaying their computations to a subsequent iteration, where potentially more (or even all)
threads are taking their path, resulting in higher utilization of execution units.
The main challenge of implementing iteration delaying is reaching a consensus among the warp threads on which path of the branch to take in each loop iteration.
Two strategies discussed are majority vote and round robin. In a majority vote, the threads of a warp communicate which branch each takes and all threads take the branch the majority would take. However, this can lead to starvation of threads in the minority. In the round robin case, the branch taken in an iteration is the branch not taken in the previous iteration.
There are various factors that affect the effectiveness and efficiency of iteration delaying, from the relative size of the branch code
relative to the other code in the loop body (the lower the ration, the lower the expected benefit of iteration delaying) to the branching pattern. One of the best branching patterns for iteration delaying is that the branch direction (per thread) alternates over iterations. Another thing to regard is that iteration delaying may destroy coalesced memory accesses in the branches, though it is unlikely to achieve memory coalescing in divergent code anyways.
Branch distribution
Iteration delaying relies on a per-thread loop that surrounds the target branch. Branch distribution can be applied to reduce the divergence of a multi-path branch on its own. This “factors out” code from the branch paths that are structurally the same, so that the total number of dynamic instructions is reduced.
Based on Code C shown in the related pattern, we can move out of the if condition the operations performed on different data:
// Code C
if(c > 0) {
a = a1;
b = b1;
} else {
a = a2;
b = b2;
}
x = x * a + b;
y = y * a + b;
In this case, the divergent code paths are smaller (in terms of operations), yielding in less branch divergence.
To benefit from branch distribution, the factored-out part needs to be large enough that the resulting benefit of convergence compensates for the overhead of the additional instructions.
