List of Metrics
POP has defined a methodology for analysis of parallel codes to provide a
quantitative way of measuring relative impact of the different factors inherent
in parallelisation. The the methodology uses a hierarchy of metrics each
one reflecting a common cause of inefficiency in parallel programs. These
metrics then allow comparison of parallel performance (e.g., over a range of
thread/process counts, across different machines, or at different stages of
optimisation and tuning) to identify which characteristics of the code
contribute to inefficiency.
The metrics are then calculated as efficiencies between 0 and 1, with higher
numbers being better. In general, we regard efficiencies above 0.8 as
acceptable, whereas lower values indicate performance issues that need to be
explored in detail.
Standard metrics
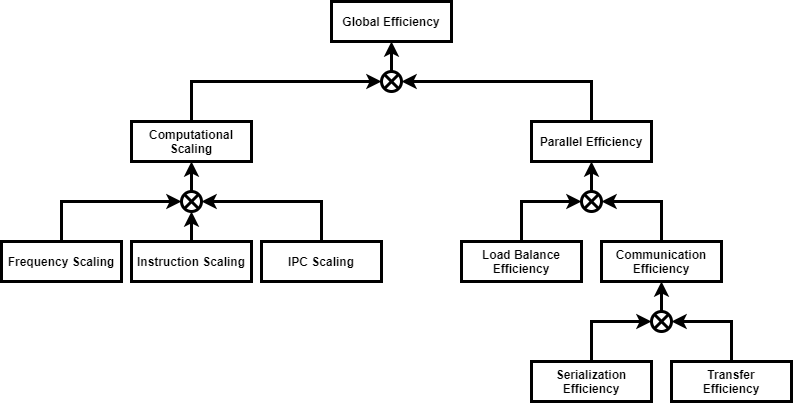
Global Efficiency:
The Global Efficiency (GE) measures the overall quality of the parallelisation.
Computation Scaling:
The Computation Scaling (CompS) computes the ratios of total time in useful
computation summed over all processes.
Instruction Scaling:
The Instruction Scaling (IS) compares total number of useful instructions to
the reference case.
IPC Scaling:
The IPC Scaling (IPCS) compares IPC to the reference case.
Frequency Scaling:
The Frequency Scaling (FS) compares processor frequencies to the reference.
Parallel Efficiency:
The Parallel Efficiency (PE) reveals the inefficiency in splitting
computation over processes and then communicating data between processes.
Load Balance Efficiency:
The Load Balance Efficiency (LBE) is computed as the ratio between Average Useful
Computation Time (across all processes) and the Maximum Useful Computation time
(also across all processes).
Communication Efficiency:
The Communication Efficiency (CommE) is the maximum, across all processes, of
the ratio between Useful Computation Time and Total Runtime.
Serialization Efficiency:
The Serialisation Efficiency (SerE) describes any loss of efficiency due to
dependencies between processes causing alternating processes to wait.
Transfer Efficiency:
The Transfer Efficiency (TE) measures inefficiencies due to time in data transfer.
Multiplicative Hybrid metrics
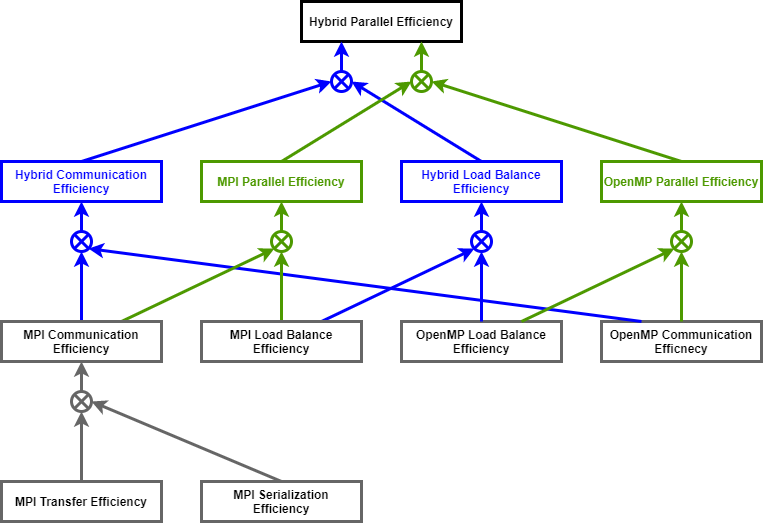
Hybrid Parallel Efficiency:
The Hybrid Parallel Efficiency (HPE) meassures the percentage of time outside
the two parallel runtimes.
Hybrid Communication Efficiency:
The Hybrid Communication Efficiency (HCE) is the maximum percentage of time
outside both parallel runtimes.
Hybrid Load Balance Efficiency:
The Hybrid Load Balance Efficiency (HLBE) is computed as the ratio between
Average Useful Computation Time and the Maximum Useful Computation Time.
MPI Parallel Efficiency:
The MPI Parallel Efficiency (MPI PE) describes the parallel execution of the
code in MPI considering that from the MPI point of view, the OpenMP runtime is
as useful as the computations.
MPI Load Balance Efficiency:
The MPI Load Balance Efficiency (MPI LBE) describes the distribution of work in
MPI processes only considering time outside MPI.
MPI Communication Efficiency:
The MPI Communication Efficiency (MPI CE) describes the loss of efficiency in
MPI processes communication only considering time outside MPI.
MPI Serialization Efficiency:
The MPI Serialisation Efficiency (MPI SE) describes any loss of efficiency
due to dependencies between processes causing alternating processes to wait.
MPI Transfer Efficiency:
The MPI Transfer Efficiency (MPI TE) measures inefficiencies due to time in
data transfer.
OpenMP Parallel Efficiency:
The OpenMP Parallel Efficiency (OpenMP PE) describes the parallel execution
of the code in OpenMP.
OpenMP Communication Efficiency:
The OpenMP Communication Efficiency (OpenMP CE) is defined as the quotient of
the Hybrid Communication Efficiency (HCE) and the MPI Communication
Efficiency (MPI CE) and thereby captures the overhead induced by the OpenMP
constructs, which represents threads synchronization and scheduling.
OpenMP Load Balance Efficiency:
The OpenMP Load Balance Efficiency (OpenMP LBE) is defined as the quotient of
the Hybrid Load Balance Efficiency (HLBE) and the MPI Load Balance
Efficiency (MPI LBE) and represents the load balance within the OpenMP part of
the program.
Additive Hybrid metrics
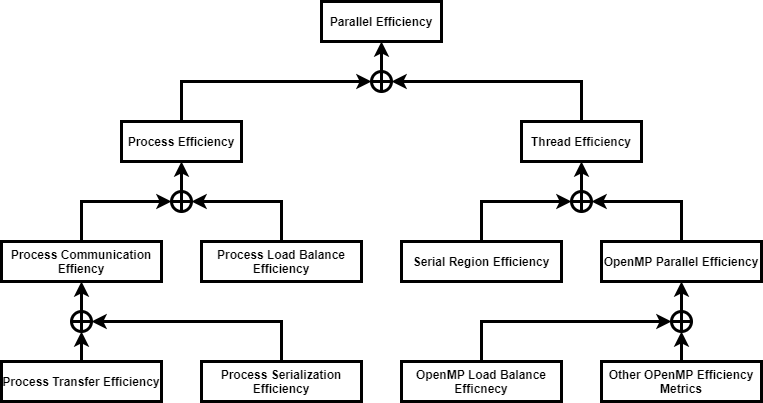
Parallel Efficiency:
Parallel Efficiency measures the overall efficiency of splitting computation over processes and threads.
Process Efficiency:
Process Efficiency considers sources of inefficiency which occur in the process parallelisation. It ignores the threads, by treating the following as useful:
Process Load Balance Efficiency:
Process load imbalance considers the time cost of imbalance of useful work
when ignoring the threads, when considering the following as useful:
Process Communication Efficiency:
Process Communication Efficiency measures the time cost
introduced by process MPI communication. It ignores any MPI within OpenMP
parallel regions, which are considered as contributing to thread inefficiency.
Process Transfer Efficiency:
Process Transfer Efficiency considers inefficiency due to time in process MPI data transfer, i.e. ignoring MPI inside OpenMP.
Process Serialization Efficiency:
The Process Serialisation Efficiency describes any loss of
efficiency due to MPI dependencies causing processes to wait.
Thread Efficiency:
Thread Efficiency considers sources of inefficiency which occur in the thread parallelisation. These inefficiencies arise when CPU cores are idle during serial computation outside OpenMP, and due to time outside useful computation within OpenMP parallel regions.
Serial Region Efficiency:
Serial Region Efficiency measures the inefficiency arising from idle cores during computation outside OpenMP.
OpenMP Parallel Efficiency:
The OpenMP Parallel Efficiency measures the cost of inefficiencies within
OpenMP parallel regions, averaged over the processes. Inefficiency is any time
spent outside useful computation within an OpenMP parallel region and can
include time in MPI.
OpenMP Load Balance Efficiency:
The OpenMP Load Balance Efficiency measures the time cost of
computational imbalance within OpenMP, averaged over the processes. This can be split into a contribution per OpenMP region.
Other OpenMP Efficiency Metrics:
The Other OpenMP Parallel Efficiency sub-metrics can be calculated based on
average values (over all threads) of non-useful time within OpenMP per source
of inefficiency.
