Performance Optimisation and Productivity
List of Best practices
These recommendations will address the holistic space form application refactoring to using or proposing new features in the system software or hardware architecture. Our holistic vision of co-design aims at addressing the issues at the level (or split between levels) that maximizes the gain at the minimal cost.
The following entries will suggest basic directions and provide links to code or raw data that can be used to further explore the options and quantify the benefits.
Align branch granularity to warps
To mitigate the problem of GPU branch divergence it is recommended to align the branch granularity to the warp size.
Effective auto vectorization
A number of methods of automatic generation of vector instructions have been developed for optimizing compilers. They allow vectorizing code without control branches or with some template branches. Consider the Automatic vectorization of a vectoring allowing to vectorize cycles without management branches. The basic idea of the Automatic vectorization consists of Loop Unroll to create copies of the original scalar expression and further replacement by vector instructions of groups of scalar instructions. Automatic vectorization is a special case of automatic paralleling where the program code is converted from a scalar implementation that processes one operation on several operand pairs at once.
Programs: For loops full auto-vectorization ·Avoiding subnormal floating-point calculations
Subnormal floating-point (FP) calculations should be avoided as they might slow down the execution time of floating-point operations significantly. This best practice discusses three solutions to avoid subnormals in an application: using flush-to-zero (FTZ) mode of the CPU, selecting an appropriate FP data type, and a numerical solution such as softening.
Using buffered write operations
Modern HPC file systems are designed to handle writing a large amount of data to a file. However, if the application performs a lot of write operations that write data in very small chunks this leads to an inefficient use of the file system’s capabilities. This becomes even more apparent if the file system is connected to the HPC system via a network. In this case each write operation initiates a separate data transfer over the network. So every time this happens one also pays the latency to establish the connection to the file system. This effect can easily sum up if a large number of small write operations happens.
Programs: CalculiX I/O (buffered) ·Chunk/task grain-size trade-off (parallelism/overhead)
A trade-off between parallelism and overhead in terms of the POP metrics corresponds to balancing the Load Balance and Communication efficiency. In general, we aim to create enough chunks (parallelism) in order to utilize all available computational resources (threads). At the same time, we need to keep the related overhead low. Less overhead is reflected by higher Communication efficiency. On the other hand, scheduling of threads at the runtime is often needed in order to balance the workload effectively. This leads to better Load Balance at the cost of the lower Communication Efficiency.
Programs: BEM4I miniApp (Chunksize 500) · BEM4I miniApp (One chunk per thread) ·Coarse grain (comp + comm) taskyfication with dependencies
This best-practice involves the creation of coarse grain tasks (including communication and computation), using task dependencies to drive work-flow execution. Parallelism is then exposed at the coarser grain level, whenever it is possible. Using as the starting point the following pattern:
Programs: FFTXlib (ompss) ·Collapse consecutive parallel regions
The main idea behind collapsing parallel regions is to reduce the overhead of the fork-join phases. This technique consists on substituting a sequence of parallel work-sharing regions with a single parallel region and multiple inner work-sharing constructs.
Compensate load imbalance with DLB
The Dynamic Load Balancing (DLB) library manages resource allocation within a computational node to address load imbalances in parallel applications. It operates transparently to both the developer and the application, adjusting the number of threads assigned to different processes as needed. Since this solution is applied at runtime, it can dynamically resolve load imbalances that arise during execution.
Programs: Pils (DLB) version ·Conditional nested tasks within an unbalanced phase
In other cases N may be small (close or equal to the number of cores) and the
granularity of do_work may be large. This happens for example in the Calculix
application from which the kernel in the figure below shows an
excerpt. In that case, the individual do_work computations correspond to the
solution of independent systems of equations with iterative methods that may
have different convergence properties for each of the systems.
Appropriate process/thread mapping to GPUs
Using the correct CPU cores to handle data transfers to and from the GPU can have a significant impact on the performance. Especially with large data transfers the bandwidth differs heavily between different NUMA domains and GPUs. This is due to the fact that on most systems GPUs are connected to a NUMA domain and therefore have a NUMA affinity.
Programs: GPU SAXPY with optimal cpu binding ·Replace OpenMP critical section with master-only execution
This best practice recommends removing the critical statement from the parallel region. This can be achieved by moving the critical region outside of the loop, often by caching per-thread results in some way, and finalising the results in a single or master only region. This trades the serialisation and lock-management overheads for some additional serial execution but will often lead to overall performance improvement due to performance gains in the parallel region.
Programs: OpenMP Critical (critical section replaced by master-only execution) ·Re-consider domain decomposition
Changing the domain decomposition may improve the communication imbalance of the application. Traditionally, domain decomposition algorithms only take into consideration the number of elements to be computed within the rank. A potentially interesting approach would be to modify the domain decomposition algorithm such that the cost function accounts for the number of elements within a domain, as well as its number of neighbours (appropriately weighted) and the communications the resulting domain must establish with them.
Programs: Communication Imbalance (rebalance) ·Dynamic loop scheduling
When parallelizing a loop which independent iterations may have different execution time, the number of iterations is large (compared to the number of cores), and the granularity of each iteration may be small. A parallelization like:
GPU align memory accesses
To achieve maximum memory bandwidth the developer needs to align memory accesses to 128 byte boundaries. The ideal situation is a sequential access by all the threads in a warp, as shown in the following figure where 32 threads in a warp access 32 consecutive words of memory.
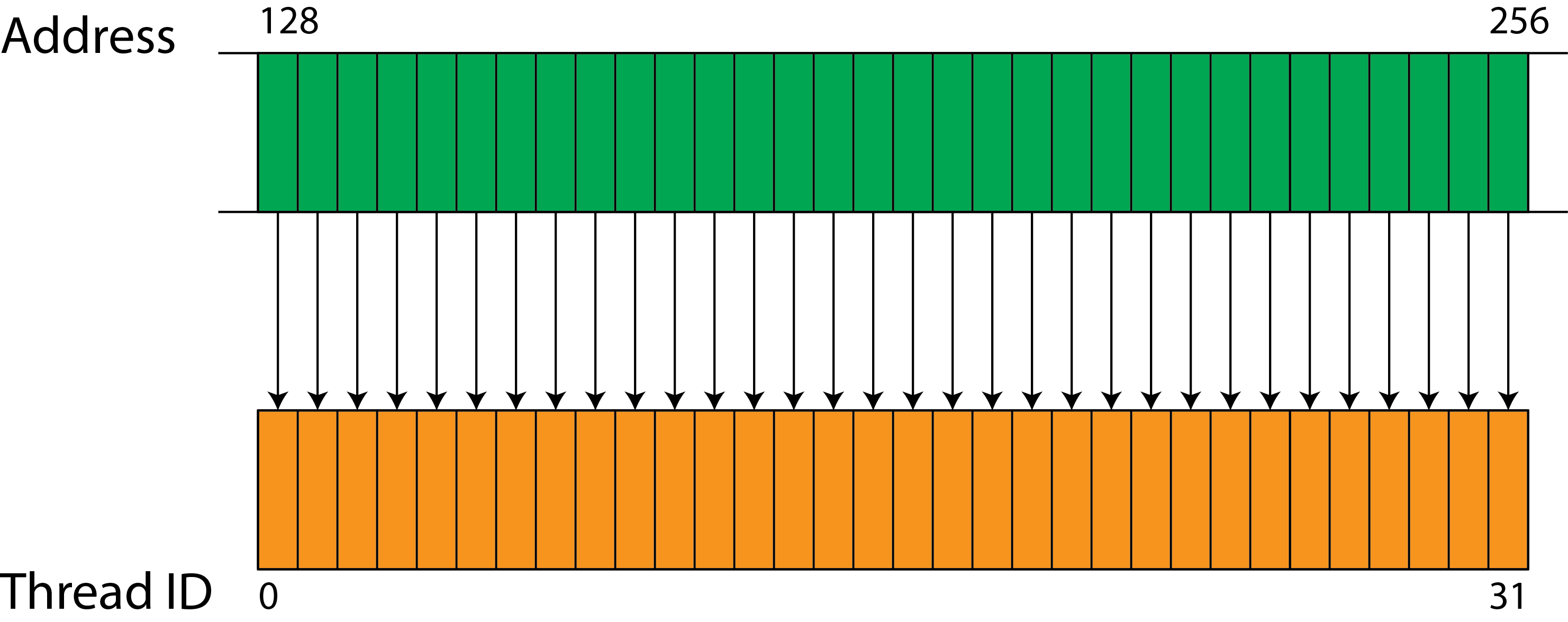 However, sequential access is not required (anymore, it was for early generations of GPGPUs), e.g a pattern like
However, sequential access is not required (anymore, it was for early generations of GPGPUs), e.g a pattern like
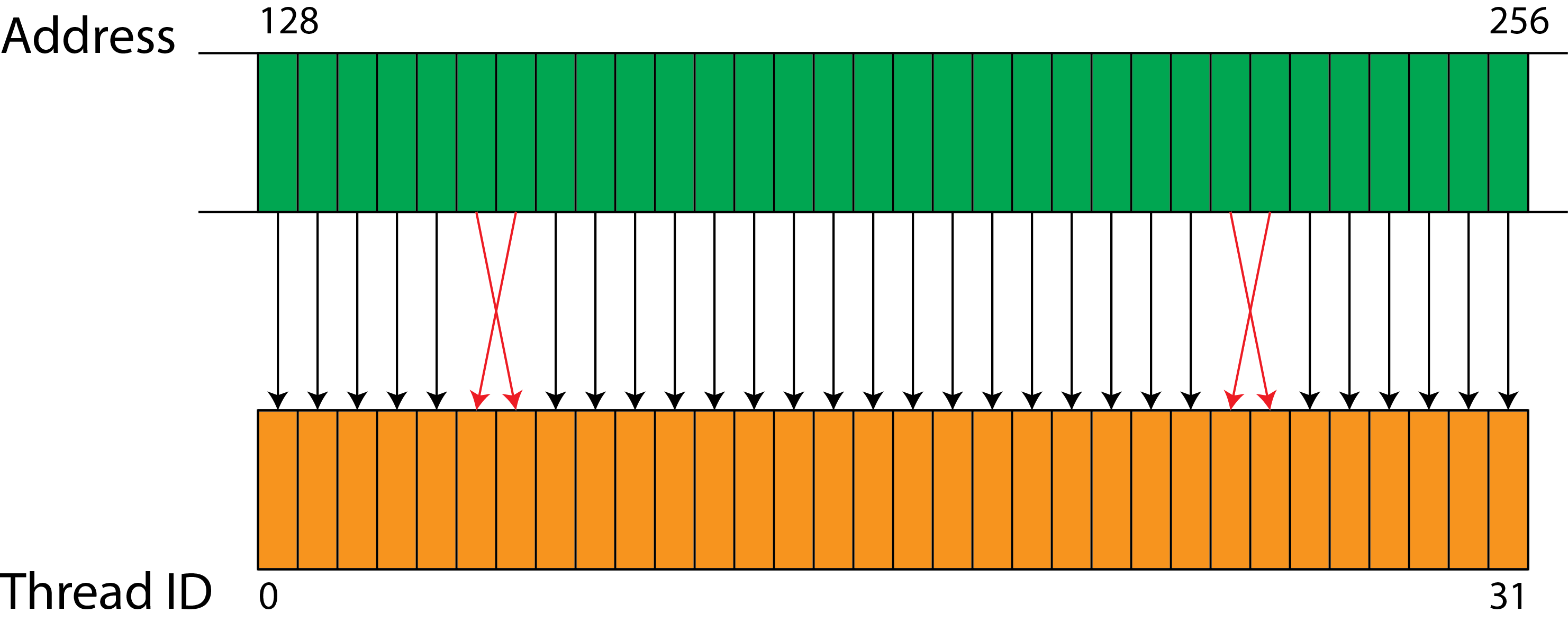 will still yield in fully coalesced memory accesses.
will still yield in fully coalesced memory accesses.
Avoidable transfers between host and GPU for MPI communication (GPU-Aware MPI)
In an iterative GPU-accelerated computation, where data is transferred between host and device in each iteration only to be exchanged via MPI, that is without any processing on the host, the transfers between host and device can be avoided by making use of MPI’s GPU-aware feature. Despite not being standardized, the two commonly used MPI implementations, OpenMPI and MPICH, and their derivatives support GPU-aware communication.
Programs: GPU Kernel GPU-aware MPI ·Leveraging OpenMP worksharing constructs
When the individual iterations of an for loop have significant differences in
runtime, a manual distribution or the naive OpenMP for loop might lead to
sub-optimal results. However, OpenMP provides several advanced worksharing
constructs that help the developer to mitigate this situation. OpenMP provides
several scheduling options to distribute the loop iterations among the threads
and, since OpenMP 4.5, the taskloop which creates tasks for the loop
iterations that are scheduled by the OpenMP runtime.
Leverage optimized math libraries
The fundamentals of this best-practice lie in the rule: Do not reinvent the wheel. If a developer recognizes a well-known math routine that possibly causes a bottleneck in the program, it is recommended to do a short research on available libraries that implement the recognized routine and suit the program.
Programs: SIFEL kernel (factorization by math library) ·MPI-I/O with pre-computed offsets for each processes
Writing unstructured data with differing amounts of data per process to a contiguous file is challenging. If the ordering of the data in the file is not of importance, one approach using MPI I/O functionalities to achieve good performance is to pre-compute per process offsets into the file so that each process can then write his local data starting from this position without interfering with the other processes.
Programs: Writing unstructured data to a contiguous file using MPI I/O with offsets ·Multidependencies in indirect reductions on large data structures
The idea behind the use of multidependencies is to split the iteration space into tasks, precompute which of those tasks have “incompatibility” (modify at least one shared node), and leverage the multidependencies feature in OpenMP to achieve at runtime a scheduling effect comparable to coloring but with a higher level of parallelism and dynamic.
Programs: Alya assembly (multidependencies) ·Usage of Numba and Numpy to improve Python's serial efficiency
When Python applications have heavy computing functions using generic data types it is possible to drastically increase sequential performance by using Numba or Numpy. Both packages can be used at the same time or separately depending on code’s needs.
Programs: Python loops (numba+numpy) · Python loops (numba) · Python loops (numpy) ·Collapsing OpenMP parallel loops
In some codes, the problem space is divided into a multi-dimensional grid on which the computations are performed. This pattern typically results in codes with multiple nested loops iterating over the grid, as shown in the following code snippet.
Programs: OpenMP nested loop collapse ·Over-decomposition using tasking
There are multiple approaches to tackle load imbalances in an application. This best practice shows how over-decomposition with e.g., OpenMP tasking can help to reduce load imbalances as an alternative to classic loop-based solutions. In the initial high-level example that has been presented in the pattern description, the workload of each iteration might be different or depending on i but is not known beforehand. Distributing the iteration across threads can then lead to load imbalances. A conventional loop-based approach could use a dynamic schedule to mitigate the imbalance by dynamically scheduling chunks of iterations to idling threads.
Programs: Sam(oa)² (Chameleon) · Sam(oa)² (OpenMP tasking) ·Overlap communication and packing/unpacking tasks with TAMPI
An easy way to implement communication and computation overlap consists on leveraging the existing communication and computational tasks, relying on task dependencies to deal with their synchronizations and link the application with the TAMPI library.
Overlapping computation and communication
Parallel applications often exhibit a pattern where computation and communication is serialized. For example, the following pseudo code performs computation on some data_A and after this computation is finished, some data_B are communicated between processes:
Parallelize packing and unpacking regions
We consider it is a good practice to taskify these operations allowing them to execute concurrently and far before the actual MPI call in the case of packs or far after in the case of unpacks. These operations are usually small and heavily memory-bandwidth bound. For that reason, we believe it is a good practice not to parallelize each one using fork-join parallel for/do blocks, because the resulting granularity would be too fine and the associated overhead would significantly affect performance. The size typically varies a lot between different pack/unpacks to/from different processes. Using a sufficiently large grain size may allow for some of these operations to be parallelized if the message is large while executing as a single task for small buffers (see dependence flow between pack and MPI_Isend() operations in the following code).
Parallel library file I/O
This best practice uses a parallel library for file I/O to write to a single binary file. A parallel library can make optimal use of any underlying parallel file system, and will give better performance than serial file I/O. Additionally, reading and writing binary is more efficiency than writing the equivalent ASCII data.
Programs: Parallel File I/O (parallel-library-mpiio-collective-access) · Parallel File I/O (parallel-library-mpiio-independent-access) · Parallel File I/O (parallel-library-netcdf-collective-access) · Parallel File I/O (parallel-library-netcdf-independent-access) · Parallel File I/O (serial-ascii) ·Parallel multi-file I/O
This best practice uses multiple files for reading and writing, e.g. one file per process. This approach may be appropriate when a single file isn’t required, e.g. when writing checkpoint data for restarting on the same number of processes, or where it is optimal to aggregate multiple files at the end.
Programs: Parallel File I/O (parallel-ascii-multifile) · Parallel File I/O (parallel-binary-multifile) · Parallel File I/O (serial-ascii) ·Porting code to GPU (iterative kernel execution)
This text describes a programming pattern for GPUs where the computation is performed iteratively. Between iterations, data exchange among MPI ranks takes place. The code implements classical domain decomposition where each patch is processed by a dedicated MPI rank using a single GPU. In an ideal case, the existing domain decomposition can be reused while the computation is performed by the GPU instead of the CPU.
Programs: CPU to GPU, OpenCL version ·Postpone the execution of non-blocking send waits operations
The recommended best-practice in this case will consist on postponing the execution of wait on send buffer as much as possible, in order to potentially overlap the send operation with the Computational phase. There are several ways we can delay this operation.
Programs: False communication-computation overlap (postpone-wait) ·Re-schedule communications
A simple way to address the issue would be to sort the list in ways that avoid such endpoint contention. Optimal communication schedules can be computed, but in practice, just starting each list by the first neighbor with rang higher that the sender and proceeding circularly to the lower ranked neighbor when the number of processes in the communicator is reached will probably reduce the endpoint contention effect.
Replacing critical section with reduction
This best practice recommends that if the critical block is performing a reduction operation, this be replaced by the OpenMP reduction clause which has a much lower overhead than a critical section.
Programs: OpenMP Critical (master) · OpenMP Critical (critical section replaced by a reduction) ·Replicating computation to avoid communication (gemm)
The best-practice presented here can be used in parallel algorithms where a large fraction of the runtime is spent calculating data on individual processes and then communicating that data between processes. For such applications, the performance can be improved by replicating computation across processes to avoid communication. A simple example can be found in molecular dynamics, where we have the computation of the interactions between N particles. The equations of motion to be solved are
Solving dynamic load balance problems
In order to dynamically balance the computational work among MPI ranks, a small set of routines must be implemented that perform the following tasks:
- measure computational load, i.e. computational cost per work package for each MPI rank
- remove and add work packages from a single MPI rank
- transfer work packages among MPI ranks
- determine the optimized distribution of work packages based on measured computational cost and current number of work packages
Spatial locality performance improvement
This best practice recommends to align data layout and data access pattern to efficiently use available resources and take advantage of e.g., the caching behavior and vectorization units of the underlying architecture.
Programs: Access Pattern Bench (optimized) ·Task migration among processes
There are multiple approaches to tackle load imbalances between processes in an application that might run on physically different compute nodes. Especially, if the workload is not known a-priori and might also dynamically change over time it is hard to apply a proper domain decomposition or rebalancing steps during the application run. Further, complete global data and workload redistribution after e.g, every iteration of a simulation might be a too expensive. This best practice presents an approach using over-decomposition with tasks and task migration to mitigate the load imbalances between processes.
Programs: Sam(oa)² (Chameleon) ·Tuning BLAS routines invocation (gemm)
In many scientific applications, parallel matrix-matrix multiplications represent the computational bottleneck. Consider the following matrix-matrix multiplication:
Programs: Tuning BLAS routines invocation ·Upper level parallelisation
When thinking about parallelizing an application, one should always try to apply parallelization on an upper level of the call tree hierarchy. The higher the level of parallelization the higher the degree of parallelism that can be exploited by the application. This best-practice shows a scenario, where moving the parallelization to an upper level improves the performance significantly.
Programs: JuKKR kloop (openmp) ·