Performance Optimisation and Productivity
GPU align memory accesses
Pattern addressed: GPU uncoalesced memory transferFor CPU-based applications, stride-1 access to memory by each thread is very efficient. However, for effective utilization of memory bandwidth on GPUs, adjacent threads must access adjacent data elements in global memory. (more...)
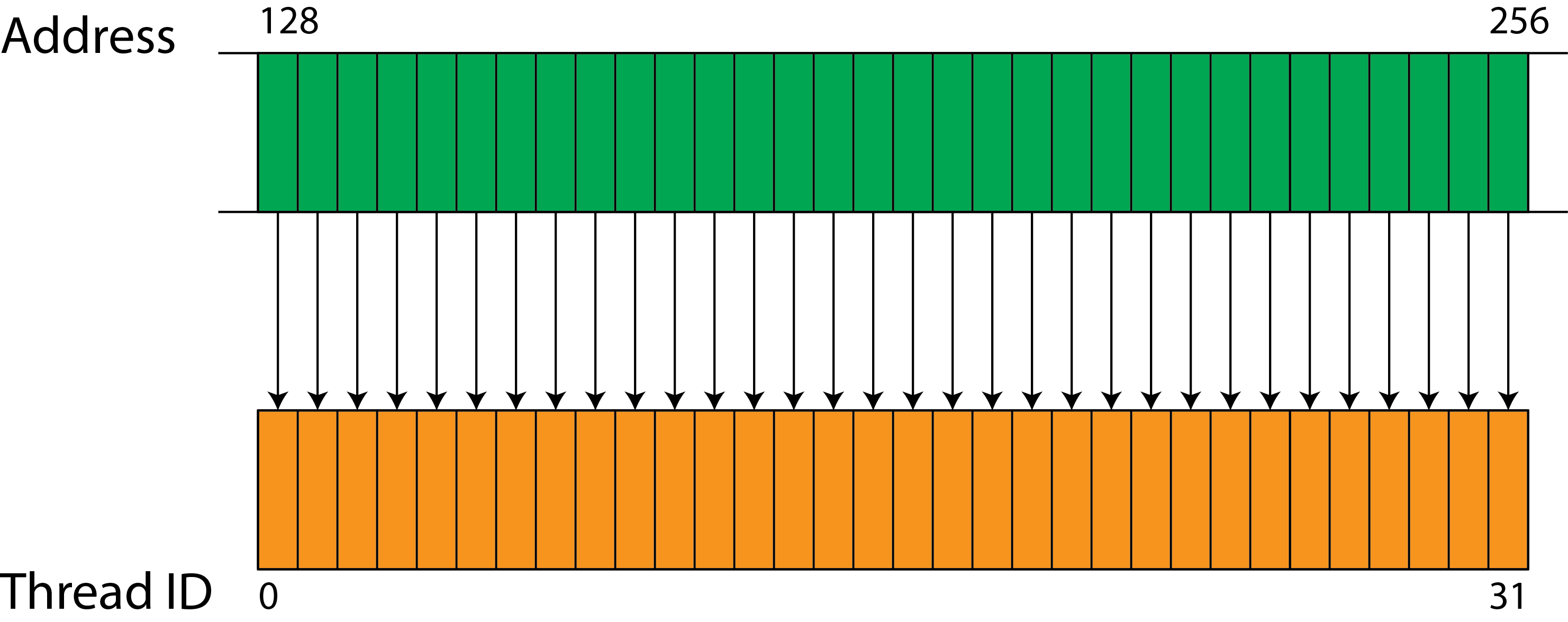
To achieve maximum memory bandwidth the developer needs to align memory accesses to 128 byte boundaries. The ideal situation is a sequential access by all the threads in a warp, as shown in the following figure where 32 threads in a warp access 32 consecutive words of memory.
 However, sequential access is not required (anymore, it was for early generations of GPGPUs), e.g a pattern like
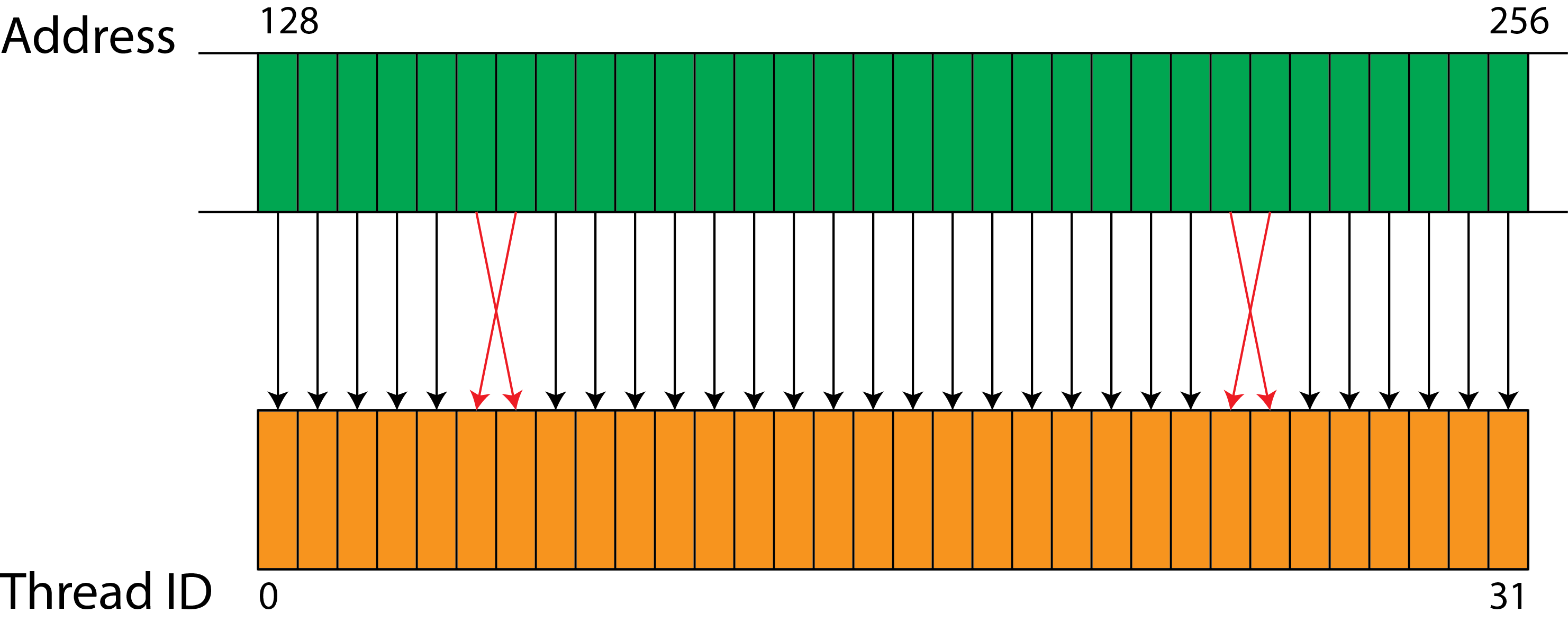
However, sequential access is not required (anymore, it was for early generations of GPGPUs), e.g a pattern like
 will still yield in fully coalesced memory accesses.
will still yield in fully coalesced memory accesses.
Sometimes the compiler can automatically align memory accesses, but usually the developer needs to tell the compiler it is safe to optimize memory accesses, e.g. by marking a pointer with the __restrict__ tag. This basically tells the compiler that the pointer is only used to access the underlying data and ensures that there is no pointer aliasing. This enables the compiler to perform various optimizations of memory accesses for this pointer, one of which is memory alignment for the desired compute capabilities.
Recommended in program(s): GPU Kernel Main ·
Implemented in program(s): GPU Kernel Optimized ·
