Performance Optimisation and Productivity
GPU uncoalesced memory transfer
For CPU-based applications, stride-1 access to memory by each thread is very efficient. However, for effective utilization of memory bandwidth on GPUs, adjacent threads must access adjacent data elements in global memory.
Coalesced memory access or memory coalescing refers to combining multiple memory accesses into a single transaction. Every successive 128 bytes ( 32 single precision words) memory can be accessed by a warp (32 consecutive threads) in a single transaction. However, the following conditions may result in uncoalesced loads, i.e., memory access becomes serialized:
- memory is not sequential
- memory access is sparse
- misaligned memory access
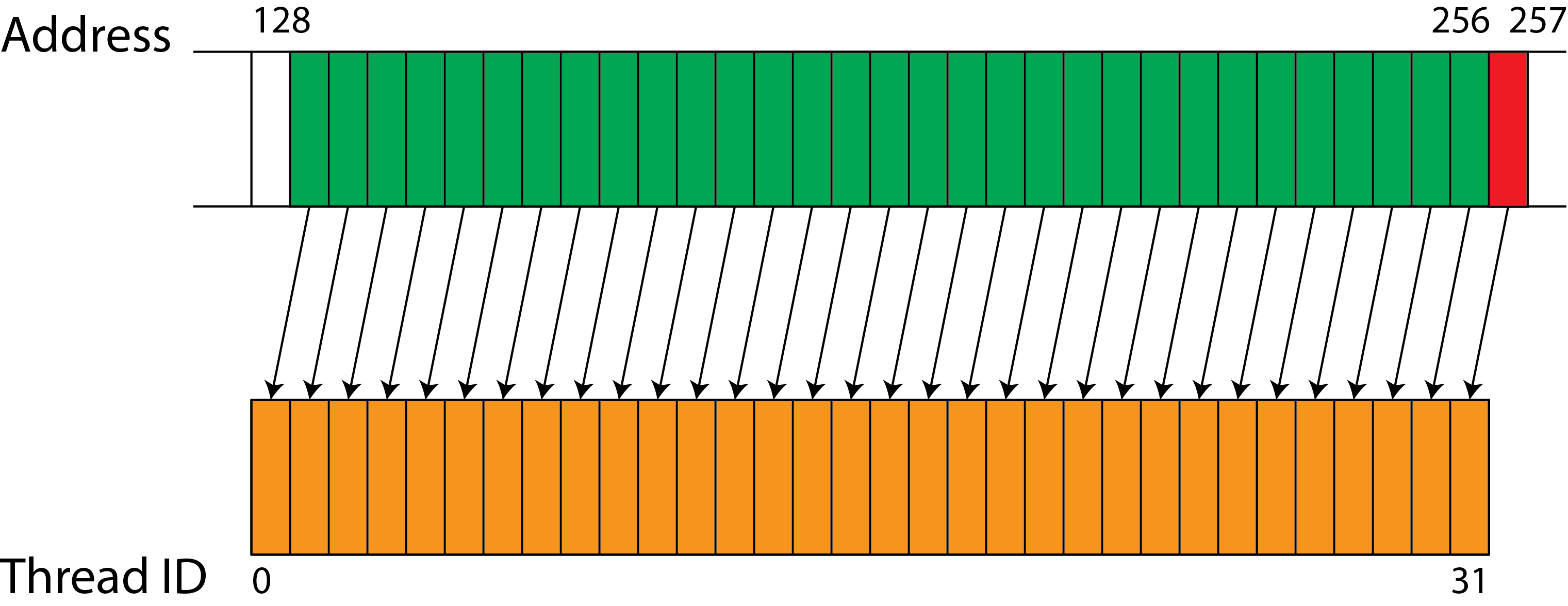
The following picture shows an example where the memory access is sequential but misaligned (to achieve coalesced memory access it is important that the starting address is a multiple of 128). Therefore, it requires one transaction to load the first 31 words, and another transaction to load the last word. Two transactions are required in total, reducing achievable memory bandwidth.