Performance Optimisation and Productivity
Spatial locality performance improvement
Pattern addressed: Spatial locality poor performanceTo achieve good performance in scientific and industrial software it is essential to review how data structures are designed inside the software and stored/loaded by the underlying programming language or machine. Although such design decisions might be beneficial in terms of readability and maintenance, it could significantly degrade performance if the way data is accessed and processed in the application does not match the data layout. There are multiple examples for a mismatch between data layout and access that might harm spatial locality of the access pattern including but not limited to the following: Arrays of Structure (AoS) or Memory layout of multi-dimensional arrays depending on the programming language. (more...)
Required condition: When a mismatch between data layout and access pattern has been identified that leads to bad spatial locality
This best practice recommends to align data layout and data access pattern to efficiently use available resources and take advantage of e.g., the caching behavior and vectorization units of the underlying architecture.
As this best practice highly depends on the code and data structures at hand we will review the example of Array of Sturctures (AoS) that has been introduced in the pattern. In order to mitigate problems arising from the strided access pattern one option would be to adapt the data structure to better fit the access pattern like illustrated in the following code snippet.
struct points {
double a[N]; // N is large
double b[N];
double c[N];
double d[N];
double e[N];
double f[N];
double g[N];
double h[N];
};
struct points pts;
void process_a(double val) {
for(int i=0; i<N; i++) {
pts.a[i] += val;
}
}
Now there is only a single struct points that contains arrays for each member variable representing the different values for N points. This design is also denoted as Structure of Arrays (SoA). Compared to the AoS the memory layout now looks different storing values for each member consecutively in memory like shown in the following example.

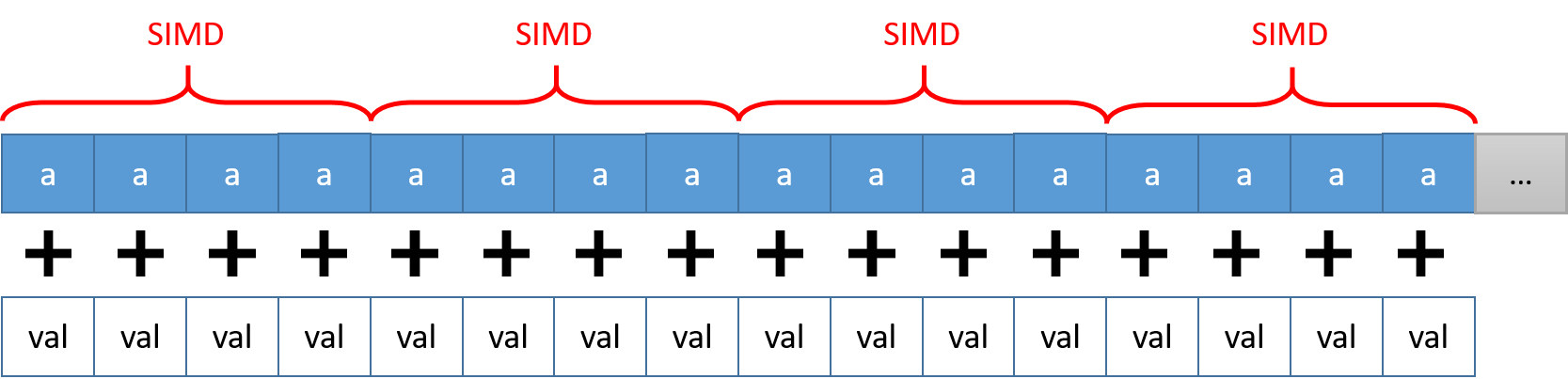
During the processing step the code can now take advantage of higher data access rates using the cache (spatial locality). If a data item a[i] is not in the cache a new cache line (64 Bytes) is loaded from memory. Thus, the next 7 values (a[i+1] … a[i+7]) can be accessed much faster. Additionally the compiler can vectorize the loop to perform multiple computations at once as shown in the following example with a SIMD length of 256.
Comparison
To demonstrate the effectiveness the following figures show the execution time, IPC values as well as L2 request and miss rate of a micro benchmark that performed AoS and SoA for different array sizes. All experiments have been conducted on a Intel Xeon Skylake Platinum CPU. As shown, the execution time can be significantly reduced by aligning the data layout and access pattern of the application.
 |
|---|
| Execution Time (sec) |
 |
|---|
| IPC |
 |
|---|
| L2 Request Rate |
 |
|---|
| L2 Miss Rate |
Recommended in program(s): Access Pattern Bench (inefficient) ·
Implemented in program(s): Access Pattern Bench (optimized) ·
