Performance Optimisation and Productivity
Conditional nested tasks within an unbalanced phase
Pattern addressed: Load imbalance due to computational complexity (unknown a priori)In some algorithms it is possible to divide the whole computation into smaller, independent subparts. These subparts may then be executed in parallel by different workers. Even though the data, which is worked on in each subpart, might be well balanced in terms of memory requirements there may be a load imbalance of the workloads. This imbalance may occur if the computational complexity of each subpart depends on the actual data and cannot be estimated prior to execution. (more...)
Required condition: When the number of iterations is small (or close to the number of workers)
In other cases N may be small (close or equal to the number of cores) and the
granularity of do_work may be large. This happens for example in the Calculix
application from which the kernel in the figure below shows an
excerpt. In that case, the individual do_work computations correspond to the
solution of independent systems of equations with iterative methods that may
have different convergence properties for each of the systems.
Asuming sufficient granularity in do_work, it may be possible to use nesting
and parallelize its internal work. In the following code we are parallelizing an
inner loop within the do_work function:
void do_work(int i)
{
#pragma omp taskloop grainsize(K)
for(int j=0; j<M; j++) {...}
}
#pragma omp parallel
#pragma omp single
#pragma omp taskloop grainsize(1)
for(i=0; i<N; i++) {
do_work(i);
}
Following figure shows a trace comparsion of executing only in parallel the external outer loop (upper trace) and enabling nested tasks (bottom trace) while keeping the outer level parallelization.
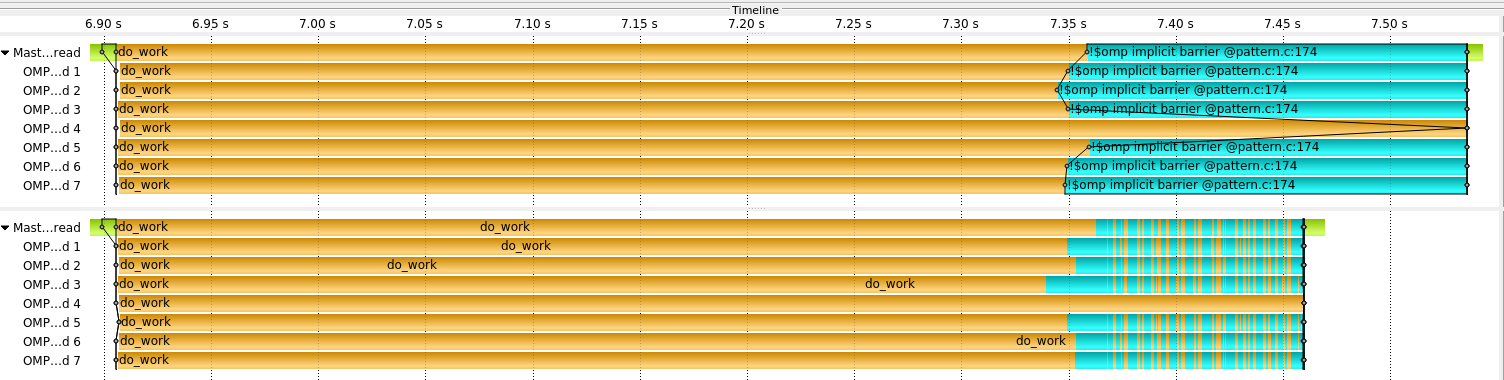
Depending on the relative value of N, #cores, and the actual cost of
do_work(i) the execution without nesting will probably fill the cores at
the beginning of the execution while only some of them at the end. A good
practice would try to execute the outer tasks serially and only activate
nesting for the long task when others have finished.
void do_work(int i)
{
#pragma omp taskloop grainsize(K) if(condition)
for(int j=0; j<M; j++) {...}
}
#pragma omp parallel
#pragma omp single
#pragma omp taskloop grainsize(1)
for(i=0; i<N; i++) {
do_work(i);
}
Where condition will evaluate to false at the beginning stages, while it will
evaluate to true at the end of the execution.
OpenMP quality of the implementation
The key to achieve the proposed good practice would rely on controlling the inner parallelism depending on the system state. Ideally this should be done automatically by the runtime, deciding how many tasks to use for each taskloop.
SW Co-design (OpenMP): The OpenMP runtime could implement an automatic mechanism to throttle the number of active tasks, or provide query services to inform about the current state of idleness, allowing to take better decisions with respect to the level of parallelism vs included overhead.
Supporting such automatic granularity control is an interesting co-design request for OpenMP runtime implementors. We have actually implemented it in the OmpSs-2 runtime.
In case the runtime does not automatically support such dynamic granularity control, the programmer can mimic it adding some control code like:
int active_tasks = 0;
do_work(int i)
{
#pragma omp atomic
active_tasks++;
for (int step=0; step<NS; step++ ) { // extra loop, spliting task in phases
gs = active_tasks > OccupancyRatio * ncores? M : M/NumTasks;
#pragma omp taskloop grainsize (gs)
for (int j=0; j<M; j++){...}
}
#pragma omp atomic
active_tasks--;
}
#pragma omp parallel
#pragma omp single
#pragma omp taskloop grainsize(1)
for(i=0; i<N; i++) {
do_work(i);
}
This is just an example and we can imagine many alternatives in how to determine the grain size, when to trigger it, etc.
This is not an ideal practice, as it mixes logic of the application and explicit scheduling decisions in the source code. We would encourage users experiencing this pattern in their application to request implementers to support the automatic granularity selection and if needed to the OpenMP ARB to take actions to ensure that implementations in that direction are allowed.
Recommended in program(s): CalculiX solver (pthreads) ·
Implemented in program(s): CalculiX solver (OpenMP) ·
