Performance Optimisation and Productivity
Compensate load imbalance with DLB
Pattern addressed: Load imbalance in hybrid programming (MPI+X)Load imbalance is a longstanding issue in parallel programming and one of the primary contributors to efficiency loss in high-performance computing (HPC) systems. It occurs when the execution time required to complete the workload assigned to different processes varies, meaning some processes finish faster than others. While the most heavily-loaded processes continue to compute, the less-loaded ones are idle, waiting for the next synchronization point, thus wasting computational resources and reducing overall efficiency. (more...)
Required condition: When the imbalance occurs intra-node
The Dynamic Load Balancing (DLB) library manages resource allocation within a computational node to address load imbalances in parallel applications. It operates transparently to both the developer and the application, adjusting the number of threads assigned to different processes as needed. Since this solution is applied at runtime, it can dynamically resolve load imbalances that arise during execution.
DLB functions across all layers of the software stack, working in collaboration with each to optimize resource utilization. It requires two levels of parallelism: the inner level is used to enhance the resource efficiency of the outer level. In typical HPC applications, this means parallelism at both the distributed memory level (e.g., across nodes) and the shared memory level (e.g., within a node). A common approach is to combine MPI (Message Passing Interface) for distributed memory systems with OpenMP for shared memory systems, allowing the strengths of both models to be leveraged.
Load imbalance can be particularly challenging in MPI applications because redistributing or moving data between processes is not straightforward. Despite this, MPI remains one of the most widely used programming models in HPC. DLB, however, is designed to be easily extended to support other parallel programming models. The integration of DLB with MPI is transparent to the application and user, leveraging MPI’s PMPI interception mechanism. Coordination with OpenMP is based on their standard public API.
DLB supports various load-balancing policies, with one of the most common being LeWI (Lend When Idle). LeWI operates by “lending” computational resources (CPUs) from an MPI process when it is idle, such as when waiting on a blocking call to another MPI process on the same node. Meanwhile, other processes on the same node that are still computing can “borrow” these idle resources.
Under this policy, each CPU is owned by a single process, and ownership does not change during the lifetime of the process. However, the owner can lend the CPU to other processes. Importantly, only the owner of a CPU can reclaim it once it has been lent.
To use DLB, developers must include the DLB API in their code. While most DLB operations are automatically handled by the interception mechanism, certain tasks, such as calling DLB_Borrow(), may require explicit programming. Additionally, developers must link with the DLB library during the compilation process and preload it before running the application.
 |
|---|
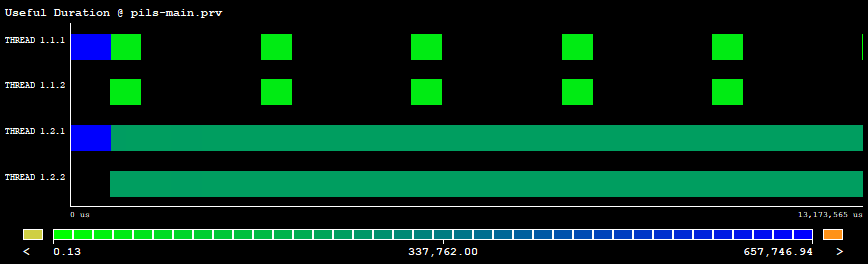
| Figure 1: Useful duration executing dlb-pils without DLB. |
 |
|---|
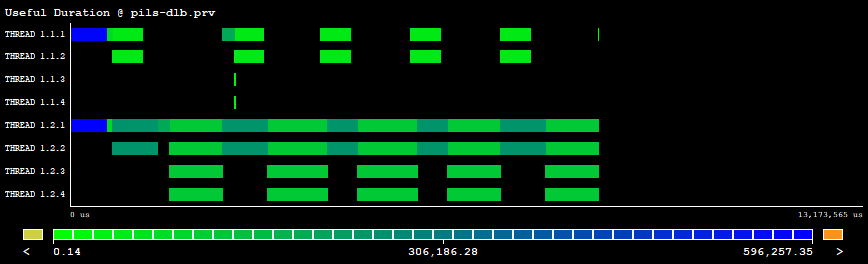
| Figure 2: Useful duration executing dlb-pils with DLB enabled. |
In Figures 1 and 2 we can see the effect of the DLB library. Figure 1 is a Paraver trace showing the useful duration of two MPI processes with two threads each. The first process finalizes its execution early before the second one and its two threads are idling while the second process still executes its corresponding code. Figure 2 shows a trace executing the same program and inputset but in this case DLB mitigates the imbalance problem by lending the unused threads from the first process to the second one (additional threads in the trace).
Recommended in program(s): Pils baseline version ·
Implemented in program(s): Pils (DLB) version ·
