Performance Optimisation and Productivity
Load imbalance in hybrid programming (MPI+X)
Usual symptom(s):- Load Balance Efficiency: The Load Balance Efficiency (LBE) is computed as the ratio between Average Useful Computation Time (across all processes) and the Maximum Useful Computation time (also across all processes). (more...)
Load imbalance is a longstanding issue in parallel programming and one of the primary contributors to efficiency loss in high-performance computing (HPC) systems. It occurs when the execution time required to complete the workload assigned to different processes varies, meaning some processes finish faster than others. While the most heavily-loaded processes continue to compute, the less-loaded ones are idle, waiting for the next synchronization point, thus wasting computational resources and reducing overall efficiency.
In the following picture we can see a Paraver trace showing the useful duration of two MPI processes with two threads each. The first process finalizes its execution early before the second one and its two threads are idling while the second process still executes its corresponding code.
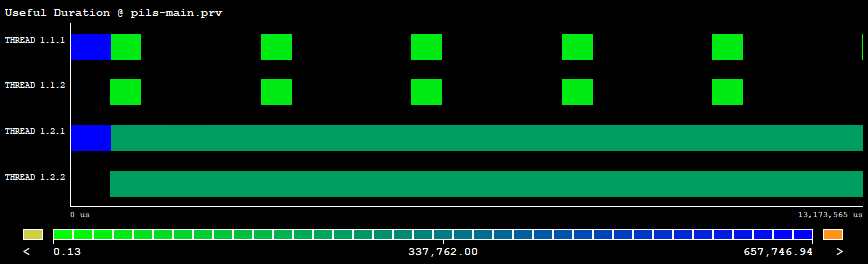 |
|---|
| Figure 1: Paraver trace: useful duration executing MPI+OpenMP dlb-pils (2 ranks x 2 threads). |
Load imbalance can arise from various factors, and these can generally be categorized into three main sources: algorithmic factors, system functionality, and system variability.
-
Algorithmic Factors: Load imbalance can be inherent to the algorithm itself, particularly due to uneven data partitioning or varying computational loads. A common example is uneven data partitioning, where the amount of data assigned to each process differs. Although mesh partitioning tools like Metis can be used to balance the data distribution, they often require heuristics to achieve optimal load balancing, which is not always straightforward. Additionally, even if a partition is well-balanced at the start, it may become imbalanced later in the execution. Computational imbalance can also arise in scenarios like sparse matrix calculations, where the distribution of non-zero values (and zeros) across processes is uneven.
-
System Functionality: System-level factors can also introduce load imbalance. For instance, differences in Instructions Per Cycle (IPC) due to variations in data locality can lead to unequal workloads among processes. While code optimizations to improve data access patterns can mitigate this issue for specific hardware and input sets, such optimizations may not be effective across different architectures or scenarios.
-
System Variability: Hardware and software variability can also significantly contribute to load imbalance. At the software level, factors like operating system noise or thread migration between cores can lead to imbalances. At the hardware level, issues such as network contention or manufacturing variations in components can cause discrepancies in processing speeds, further exacerbating load imbalance. Since these types of imbalances are difficult to predict and cannot be addressed through static methods, only dynamic mechanisms can help reduce or manage their impact on performance.
To address load imbalance, several strategies are commonly used, each targeting different aspects of the problem. Two major approaches are data-load balancing and computational-load balancing, each with its own advantages and limitations.
-
Data-Load Balancing: This approach involves redistributing the data among processes to achieve a more even load distribution. It is one of the most widely used techniques in current solutions, such as repartitioning the mesh (e.g., PAMPA) or redistributing data (e.g., Adaptive MPI). However, data movement and mesh partitioning are costly operations, making this approach more effective for coarse-grain load imbalance, where large-scale redistributions can be tolerated. While effective, it can be computationally expensive and may not address finer-grained load imbalances efficiently.
-
Computational-Load Balancing: In contrast, computational-load balancing focuses on dynamically allocating more computational resources to processes with higher loads in order to balance the overall execution time. This strategy is particularly useful for fine-grained load balancing, as it allows for quicker adjustments compared to data movement. Since shifting computational resources is generally less costly than moving large data sets, this approach is better suited for situations where load imbalances are less predictable or fluctuate frequently.
- When the imbalance occurs intra-node ⇒ Compensate load imbalance with DLB
