Performance Optimisation and Productivity
Task migration among processes
Pattern addressed: Dynamic load imbalance in MPIThis pattern focuses on the temporal evolution of load imbalances (LI). One possible scenario is the growth of LI over time, i.e. a gradual reduction of the computational performance. This reduction might happen at a slow rate so that it does not immediately catch the attention of the programmer. (more...)
Required condition: If a work imbalance is present between processes and global rebalancing steps might be too expensive
Pattern addressed: Load imbalance due to computational complexity (unknown a priori)In some algorithms it is possible to divide the whole computation into smaller, independent subparts. These subparts may then be executed in parallel by different workers. Even though the data, which is worked on in each subpart, might be well balanced in terms of memory requirements there may be a load imbalance of the workloads. This imbalance may occur if the computational complexity of each subpart depends on the actual data and cannot be estimated prior to execution. (more...)
Required condition: If a work imbalance is present between processes and global rebalancing steps might be too expensive
There are multiple approaches to tackle load imbalances between processes in an application that might run on physically different compute nodes. Especially, if the workload is not known a-priori and might also dynamically change over time it is hard to apply a proper domain decomposition or rebalancing steps during the application run. Further, complete global data and workload redistribution after e.g, every iteration of a simulation might be a too expensive. This best practice presents an approach using over-decomposition with tasks and task migration to mitigate the load imbalances between processes.
The following scenario shows ranks creating work items with varying workload. The amount of tasks and the workload might not be known a-priori. Although, it might be possible to balance the load within each rank there is still an observable load imbalance between ranks.
Sketch:

Trace:
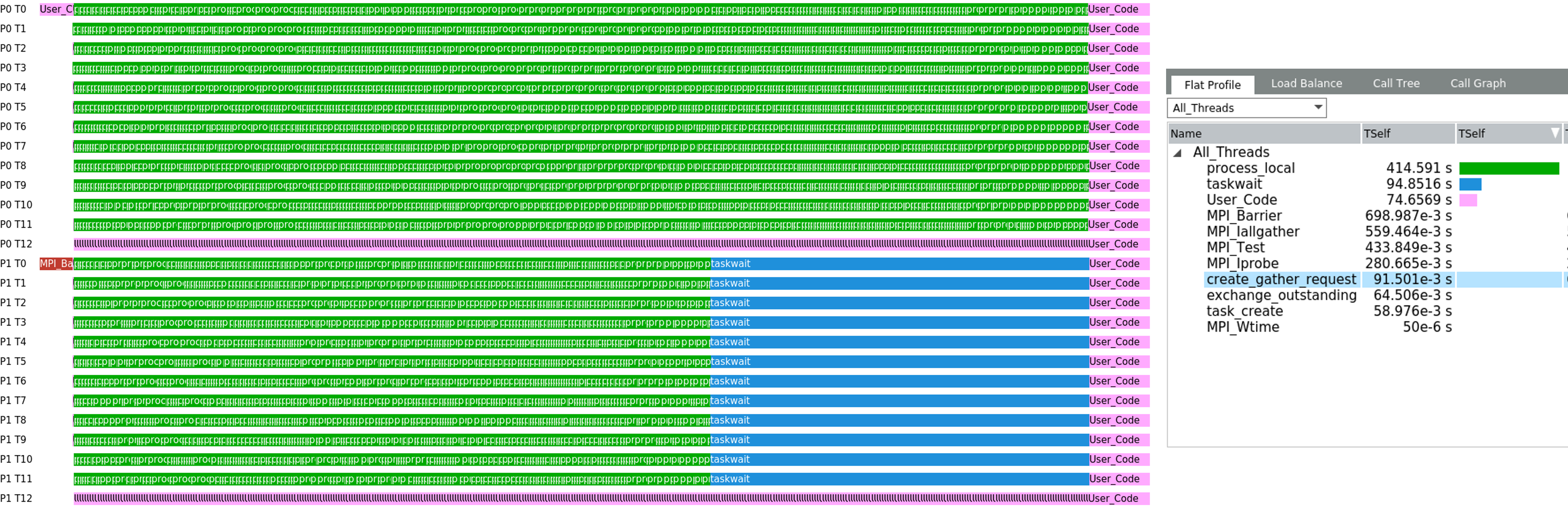
Via introspection at run time it is possible to detect emerging imbalances using a suitable metric representing the workload on each rank (here: number of tasks). By dynamically migrating tasks to underloaded ranks at run time it is possible to balance the load like shown in the following figure and trace.
Sketch:

Trace:

However, it should be noted that migrating tasks and data required to execute these tasks between processes or even compute nodes in a network is associated with some overhead (depending on latency and bandwidth). It is desired to detect the imbalance and migrate as soon as possible to be able to overlap the communication with useful computation as much as possible.
Recommended in program(s): Sam(oa)² (OpenMP tasking) · Sam(oa)² (work-sharing) ·
Implemented in program(s): Sam(oa)² (Chameleon) ·
