Performance Optimisation and Productivity
Parallel multi-file I/O
Pattern addressed: Sequential ASCII file I/OIn this pattern data held on all processes is read or written to an ASCII file by a single process. This is inefficient for several reasons: (more...)
Required condition: In a per process checkpoint/restart phase
This best practice uses multiple files for reading and writing, e.g. one file per process. This approach may be appropriate when a single file isn’t required, e.g. when writing checkpoint data for restarting on the same number of processes, or where it is optimal to aggregate multiple files at the end.
A strategy of reading or writing one file per process can give good performance, and avoids the need to communicate data between processes. However, opening many files for read and write operations can be inefficient, in which case a parallel file I/O library is likely to give better performance. Experimentation is necessary to decide which approach is best.
If adopting a multi file approach then using local file systems will typically give better performance, or it may be necessary to use a small subset of processes for file I/O.
The following pseudo-code shows the structure of the file I/O when writing
data. Each process opens a file, and then writes data held in array data to
it. Each file has a unique name based on the process rank.
get_my_process_id(proc_id)
filename = "file_" + to_string(proc_id)
open_file(filename)
write_data_to_file(data, filename)
close_file(filename)
The process is reversed when reading data from file, as follows.
get_my_process_id(proc_id)
filename = "file_" + to_string(proc_id)
open_file(filename)
read_data_from_file(data, filename)
close_file(filename)
The following timelines show this best practice on 48 processes, where data is firstly written to multiple files, and then read back from the files, for 100,000 double precision values per process. The timelines were generated on one 48 core compute node of MareNostrum4, which uses the IBM General Parallel File System (GPFS) via one 10 GBit fiber link. Each timeline is 200ms long. For comparison, the same write and read operations using the Sequential ASCII file I/O pattern take 8.5s.
In this first timeline the files contain ASCII data.

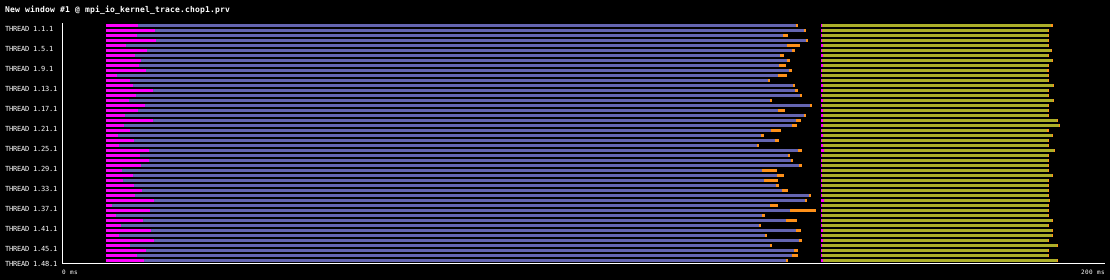
The next timeline shows the behaviour when writing and reading binary data, the file I/O takes around 40ms. As expected, writing and reading binary data is significantly quicker that ASCII data.

The final timeline repeats file I/O using binary data, illustrating that sometimes odd behaviour is observed. In this case one process requires an unusually large amount of time to open a file for reading, as a result the file I/O takes around 70ms.

Implemented in program(s): Parallel File I/O (parallel-ascii-multifile) · Parallel File I/O (parallel-binary-multifile) · Parallel File I/O (serial-ascii) ·
