Performance Optimisation and Productivity
Sequential ASCII file I/O
In this pattern data held on all processes is read or written to an ASCII file by a single process. This is inefficient for several reasons:
- Data must be communicated to the file I/O process from all other processes, one at a time.
- It is more expensive to read/write ASCII data compared to binary files.
- It does not make use of any available parallel file system.
The following pseudo-code shows the structure of the file I/O when writing
data. Data held in array data on each process is written to a single file by
process 0. Process 0 opens the file, saves its data, and then sequentially
receives and saves data from other processes.
get_my_process_id(proc_id)
get_number_of_processes(n_proc)
if proc_id == 0
filename = "file.txt"
open_file(filename)
write_ascii_data_to_file(data, filename)
for proc = 1, n_proc-1
receive_data(data, proc)
write_ascii_data_to_file(data, filename)
end for
close_file(filename)
else
send_data(data, 0)
end if
The process is reversed when reading data from file, as follows.
get_my_process_id(proc_id)
get_number_of_processes(n_proc)
if proc_id == 0
filename = "file.txt"
open_file(filename)
read_ascii_data_from_file(data, filename)
for proc = 1, n_proc-1
read_ascii_data_from_file(data, filename)
send_data(data, proc)
end for
close_file(filename)
else
receive_data(data, 0)
end if
The following timeline shows this pattern on 48 MPI processes, first writing 100,000 double precision values per process to file, followed by reading the data back from the file.

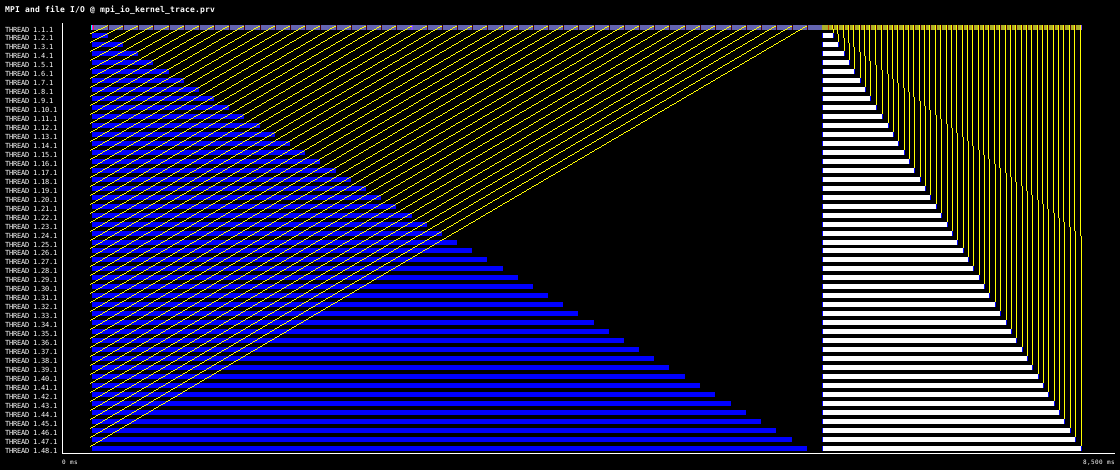
Data communications between processes is via MPI_Send and MPI_Recv. The
part of the timeline where processes are waiting in MPI_Send calls
corresponds to writing data to the file, for the remainder of the timeline
processes wait in MPI_Recv to receive data from process 0. The timeline is
8.5s long, and is show with communication lines.
- Parallel library file I/O
- In a per process checkpoint/restart phase ⇒ Parallel multi-file I/O
- Parallel File I/O (parallel-ascii-multifile)
- Parallel File I/O (parallel-binary-multifile)
- Parallel File I/O (parallel-library-mpiio-collective-access)
- Parallel File I/O (parallel-library-mpiio-independent-access)
- Parallel File I/O (parallel-library-netcdf-collective-access)
- Parallel File I/O (parallel-library-netcdf-independent-access)
- Parallel File I/O (serial-ascii)
