Performance Optimisation and Productivity
Parallel library file I/O
Pattern addressed: Sequential ASCII file I/OIn this pattern data held on all processes is read or written to an ASCII file by a single process. This is inefficient for several reasons: (more...)
This best practice uses a parallel library for file I/O to write to a single binary file. A parallel library can make optimal use of any underlying parallel file system, and will give better performance than serial file I/O. Additionally, reading and writing binary is more efficiency than writing the equivalent ASCII data.
Two obvious choices of parallel libraries are MPI I/O and NetCDF, the latter has advantages in terms of portability.
The following pseudo-code shows the structure of the file I/O when writing
data. In parallel all processes open a single file, and then write size
elements held in array data to it. In this example size is constant across
all processes.
get_my_process_id(proc_id)
offset = proc_id * size * sizeof(double)
filename = "data_file"
open_file(filename)
parallel_write_to_file(data, offset, filename)
close_file(filename)
The process is reversed when reading data from file, as follows.
get_my_process_id(proc_id)
offset = proc_id * size * sizeof(double)
filename = "data_file"
open_file(filename)
parallel_read_from_file(data, offset, filename)
close_file(filename)
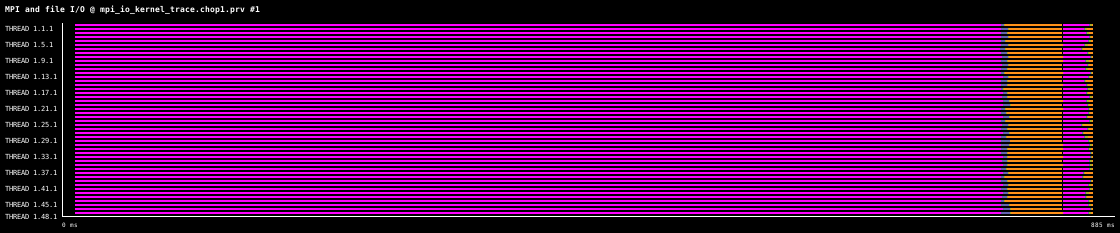
The following timelines show this best practice when implemented using MPI I/O and NetCDF, in each case data is first written to file, and then read back into memory, with the same amount of data written and read each time. For each parallel library the file writing and reading can be either collective or independent. For collective file access all processes in the communicator must call the collective I/O function, which can give performance benefits. For independent file access individual processes can write or read.
The following timelines show the file write and read for MPI I/O, firstly for collective access, and then for independent access, for 100,000 double precision values per process. The data was collected on one 48 core compute node of MareNostrum4, which uses the IBM General Parallel File System (GPFS) via one 10 GBit fiber link. For comparison, the same write and read operation using the Sequential ASCII file I/O pattern takes 8.5s.


The timelines shows 200ms of execution for collective access (above) and 110ms for independent access (below). The collective access case takes longer to open the file, and to write and read data.

The next two timelines respectively show NetCDF collective and independent file access, each timeline shows 900ms of execution, for this case NetCDF takes considerably longer than MPI I/O.
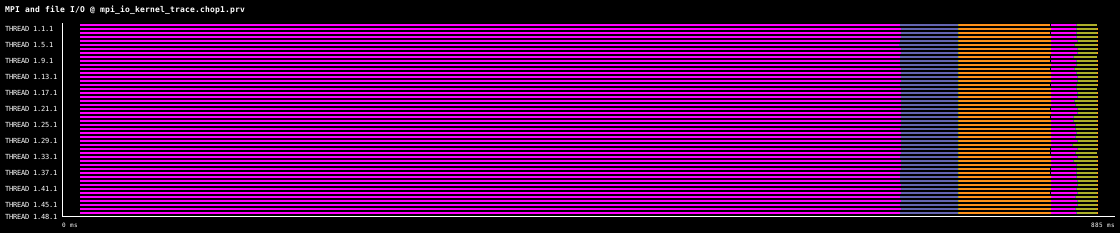
The initial file open is longer for the collective access, but the writing is faster.
Implemented in program(s): Parallel File I/O (parallel-library-mpiio-collective-access) · Parallel File I/O (parallel-library-mpiio-independent-access) · Parallel File I/O (parallel-library-netcdf-collective-access) · Parallel File I/O (parallel-library-netcdf-independent-access) · Parallel File I/O (serial-ascii) ·
