Performance Optimisation and Productivity
Upper level parallelisation
Pattern addressed: Sequence of fine grain parallel loopsThis pattern applies to parallel programming models based on a shared memory environment and the fork-join execution model (e.g., OpenMP). The execution of this kind of applications is initialy sequential (i.e., only one thread starts the execution of the whole program), and just when arriving at the region of the code containing potential parallelism, a new parallel region is created and multiple threads will start the execution of the associated code. Parallel execution usually will distribute the code among participating threads by means of work-sharing directives (e.g., a loop directive will distribute the loop iteration space among all threads participating in that region). (more...)
Required condition: When an upper-level parallelizable loop exists
When thinking about parallelizing an application, one should always try to apply parallelization on an upper level of the call tree hierarchy. The higher the level of parallelization the higher the degree of parallelism that can be exploited by the application. This best-practice shows a scenario, where moving the parallelization to an upper level improves the performance significantly.
Based on the Code C presented in the related pattern, the solution to yield a more optimized parallelization is to move the parallelization out of the loop over all spatial elements and parallelize the iteration space of this loop instead:
void code_C() {
for (int t=0; t<MAX_TIME; t+= deltaT) {
#pragma omp parallel for
for (int i=0; i<MAX_ELEMS; i++) {
BLAS_kernel_A(i); // force sequential call or link
}
#pragma omp parallel for
for (int i=0; i<MAX_ELEMS; i++) {
BLAS_kernel_B(i); // force sequential call or link
}
#pragma omp parallel for
for (int i=0; i<MAX_ELEMS; i++) {
BLAS_kernel_C(i); // force sequential call or link
}
}
}
As a result the overhead of forking and joining the parallel worker threads is only payed once per loop instead of MAX_ELEMS times per loop and the parallelization is significantly more efficient.
We implemented this best practice in a miniapp extracted from the KKRhost code which is part of the Juelich KKR code family (JuKKR) after we identified a performance issue related to the pattern Sequence of fine grain parallel loops (see #3). The results are shown in the figure below.
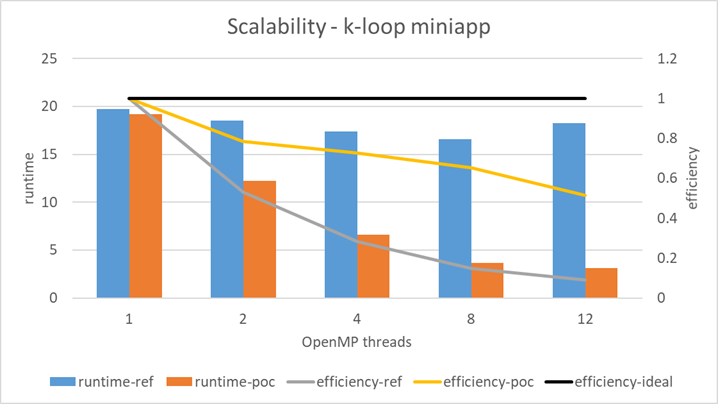
While the reference version of the code did not scale well with an increasing number of OpenMP threads, our modified version according to the presented best practice enables scalability and yields a speedup up to 6x with 12 threads.
Recommended in program(s): JuKKR kloop (original) ·
Implemented in program(s): JuKKR kloop (openmp) ·
You may continue with: Collapse consecutive parallel regions ·
