Performance Optimisation and Productivity
Multidependencies in indirect reductions on large data structures
Pattern addressed: Indirect reductions with atomic or critical constructs on large data structuresA pattern that appears on many codes computing on a grid of topologically connected nodes is the reduction of values on the nodes with possible multiple contributions from neighboring nodes. This pattern typically results in codes with reduction operations through indirection on a large array that use atomic or critical constructs to avoid the potential data race when updating it. (more...)
Required condition: This best-practice can be applied when the use of atomic induces low IPC.
The idea behind the use of multidependencies is to split the iteration space into tasks, precompute which of those tasks have “incompatibility” (modify at least one shared node), and leverage the multidependencies feature in OpenMP to achieve at runtime a scheduling effect comparable to coloring but with a higher level of parallelism and dynamic.
Precomputing the incompatibilities is an additional code to be written and may represent an overhead. In any case, if the topology is relatively invariant this can be amortized over many iterations. We show an example of how it can be done using OmpSs in alya-asm program.
This best practice could be applied to many codes computing on a grid of topologically connected nodes where a reduction of values on the nodes with possible contributions from neighboring nodes is performed. These codes present reduction operations through indirection on a large array. Examples of these codes are finite element codes (such as Alya), n-body codes, or in graph processing codes when mutual exclusion is needed when accessing neighbors (such as SPECFEM3D).
The parallelization of the mentioned reduction operation would look like:
#pragma omp parallel masked
for (i = 0; i<SIZE; i++) {
NN = neighs[i].size;
#pragma omp task depend(iterator(it=0:NN), mutexinoutset: neighs[it]) firstprivate(NN,i) priority(NN)
for (int n=0; n<NN; n++) {
type_t contribution = f(current_state, i, n);
next_state[get_index(i,n)] += contribution;
}
}
The use of multidependencies allows avoiding the use of atomic or critical OpenMP constructs when updating next_state array, that could induce a low IPC if the computation of the contribution is not much longer than the update itself. The benefits of the use of multidependencies when compared to the use of atomic can be seen in the following chart corresponding to the alya-asm program for a different number of threads and chunksizes:
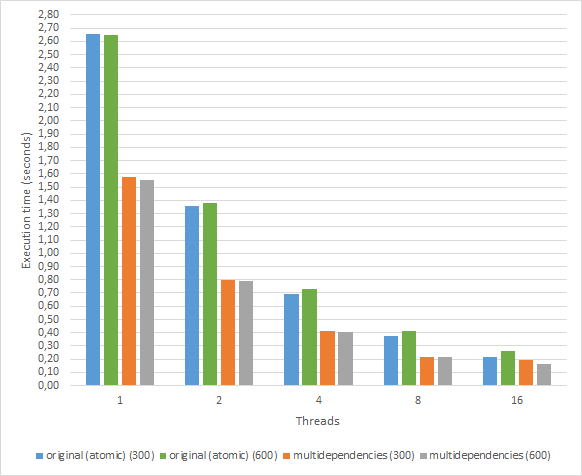 |
|---|
| Figure 1: Execution time in seconds for 1, 2, 4, 8 and 16 thread execution. |
At this point, a comparison in terms of POP performance metrics would be great but the multidependencies version is implemented in OmpSs (there is still no OpenMP compiler/runtime supporting multidependencies) and, thus, POP metrics can not be directly generated.
A comparison of both approaches is also shown in this paper where other strategies to implement this loop parallelism, like coloring or substructuring techniques to circumvent the race condition, are also discussed. The main drawback of the first technique is the IPC decrease due to bad spatial locality. The second technique avoids this issue but requires extensive changes in the implementation.
Recommended in program(s): Alya assembly (master) ·
Implemented in program(s): Alya assembly (multidependencies) ·
