Performance Optimisation and Productivity
Comparison of the original code using atomics and the multidependencies version
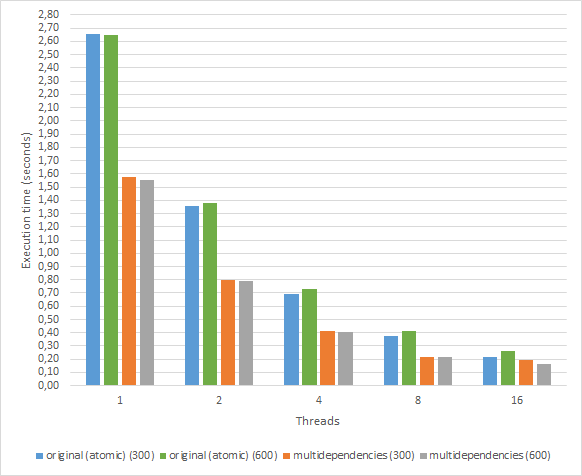
We have compared original (atomic) and multidependencies implementations within the alya-asm application for a different number of threads. Two different chunk-sizes (the best performing ones) are shown for each implementation.
 |
|---|
| Execution Time (sec) |
The execution times are measured with the SYSTEM_CLOCK call (see https://gcc.gnu.org/onlinedocs/gfortran/SYSTEM_005fCLOCK.html) embedded into the source code. Each bar represents the average execution time of 10 diffferent runs of the assembly loop.
The experiments have been conducted in a node with the following characteristics:
- 2x E5-2670 SandyBridge-EP 2.6GHz cache 20MB 8-core
- 8x 16G DDR3-1600 DIMMs (8GB/core) Total RAM: 128GB/node
As it can be seen, the best performing option for all number of threads is the use of multidependencies.
In the following figures we show a detailed view of the results for ATOMIC (base case) implementation to highlight the tipical symptoms that one will encounter when widely making use of ATOMIC constructs in the code.
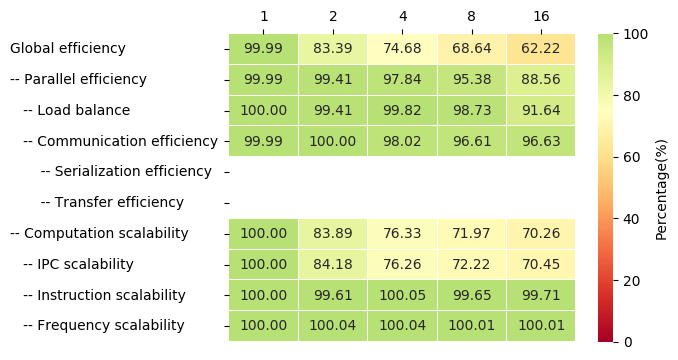
Next figure shows the Efficiency Table with the POP metrics for the studied number of threads (1 to 16, the maximum number of threads available in the considered machine):
 |
|---|
| Efficiency Table (ATOMIC) |
As it can be seen the most limiting factor when we scale is the IPC. This is because of the synchronizations forced by the ATOMIC constructs.
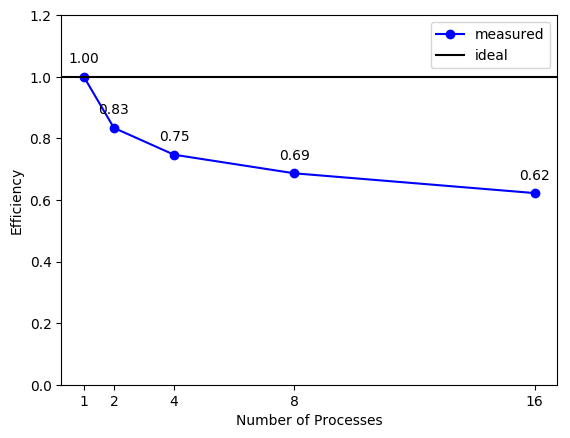
Next figure shows the overall efficiency of the application compared with the ideal one in a graphical way:
 |
|---|
| Efficiency (ATOMIC) vs ideal |
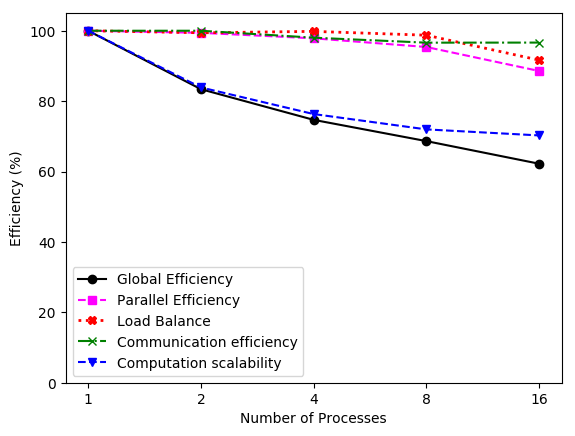
Next figure shows the overall global efficiency together with the main metrics that influence it:
 |
|---|
| Efficiency (ATOMIC) with POP metrics |
As it can be seen again, the Global Efficiency is limited by the Computation Scalability (driven by the IPC scalability as it can be seen in the next plot).
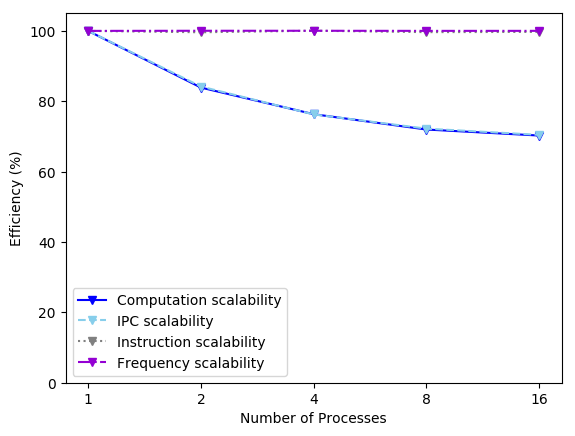 |
|---|
| Scalability (ATOMIC) |
To finish with the ATOMIC version analysis, next figure presents the Speedup plot:
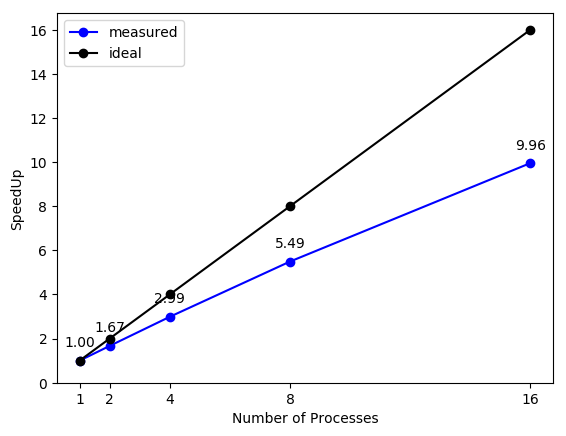 |
|---|
| Speedup (ATOMIC) |
