Performance Optimisation and Productivity
False communication-computation overlap initial analysis
The dimension of the false overlap exposed by the program will depend on the SIZE and RATIO input parameters.
The following figure shows an example of a single iteration with 4 processors
in Marenostrum IV. We used SIZE=1024*1024*4 and RATIO=0.2, and the
communication pattern explained in the program description. Thus, ranks 1
and 2 communicate between them, as well as ranks 3 and 4.
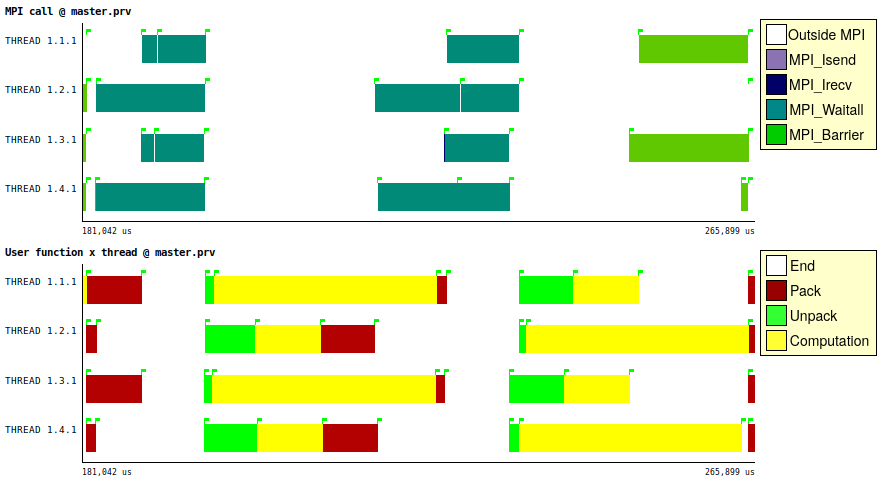
The upper trace shows the MPI calls. Isend and Irecv take a small amount of time and cannot be seen, but are located just in front of the Waitalls. The iteration ends with a Barrier. The lower trace depicts the calls to Pack, Unpack and Computation functions.
In the traces we can see how ranks 1 and 3 perform two Waitalls after the first pack, and ranks 2 and 4 do the same after the second pack. At those points, they could start to unpack and compute instead of waiting, reaching the final barrier quickly.
The following chart shows the POP efficiencies of the kernel. In particular, this program suffers from Communication efficiency, both in terms of serialization and transfer.
| Master | |
|---|---|
| Parallel efficiency | 61.69% |
| ⤷Load balance | 98.89% |
| ⤷Communication eff. | 62.38% |
| ⤷Serialization eff. | 79.40% |
| ⤷Transfer eff. | 78.57% |
The serialization loss is caused by the dependency between the neighbouring ranks, caused by the algorithm used in the program. Serialization is not addressed in the kernel. Transfer loss comes from the false overlap of communication and computation, and is solved in the postpone-wait version.
