Performance Optimisation and Productivity
False communication-computation overlap with postponed waits
The proposed best-practice addresses the problem by delaying the wait for the Isends after the end of the Computation calls. The result is shown in the following picture:
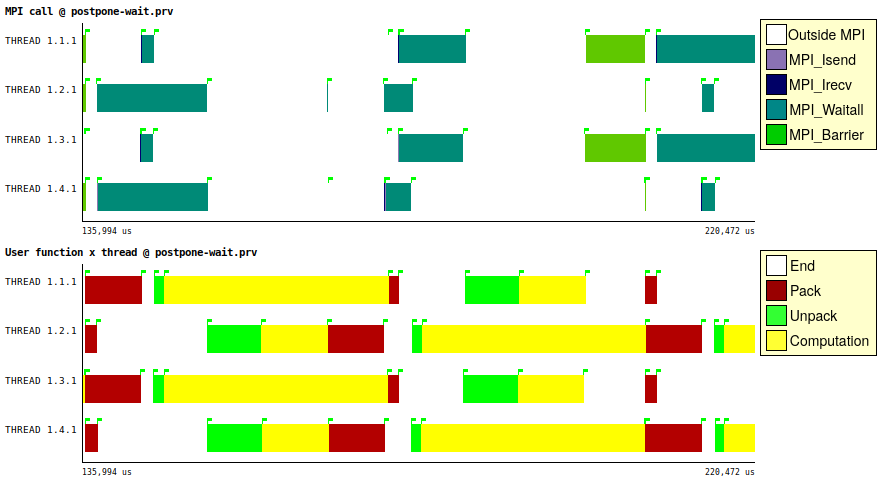
The traces show an effective overlap of communication and computation. At the beginning, ranks 1 and 3 start to unpack and compute while the others are still waiting for their Irecv. After the second pack, ranks 2 and 4 are able to start the work sooner, for the same reason. The time spend in the Waitalls for the Isend operations is drastically reduced and every rank reaches the final Barrier sooner.
The following chart shows the POP efficiencies of the kernel. Compared to the master version, the postpone-wait improved the Transfer efficiency, boosting the Communication and Parallel efficiencies.
| Master | Postpone-wait | |
|---|---|---|
| Parallel efficiency | 61.69% | 72.63% |
| ⤷Load balance | 98.89% | 98.41% |
| ⤷Communication eff. | 62.38% | 73.80% |
| ⤷Serialization eff. | 79.40% | 79.01% |
| ⤷Transfer eff. | 78.57% | 93.41% |
