Performance Optimisation and Productivity
GPU affinity on one node with 4 GPUs (JUWELS Booster)
This experiment shows the difference in runtimes is shown between running with default CPU binding and manual binding to NUMA domains.
Launch configuration
Both runs were launched with 4 MPI tasks, filling up one node with 4 GPUs. Each task offloaded to one GPU.
The run including binding the tasks to the NUMA domains was launched as follows:
srun --cpu-bind=map_ldom:3,1,5,7 ./kernel.exe 8000000000
System
JUWELS Booster compute node
- CPU: AMD EPYC 7402 processor; 2 sockets, 24 cores per socket (2 threads per core)
- GPU: 4 × NVIDIA A100 Tensor Core GPU with 40 GB
- GPU NUMA affinity:
| GPU | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| NUMA domain | 3 | 1 | 7 | 5 |
Results
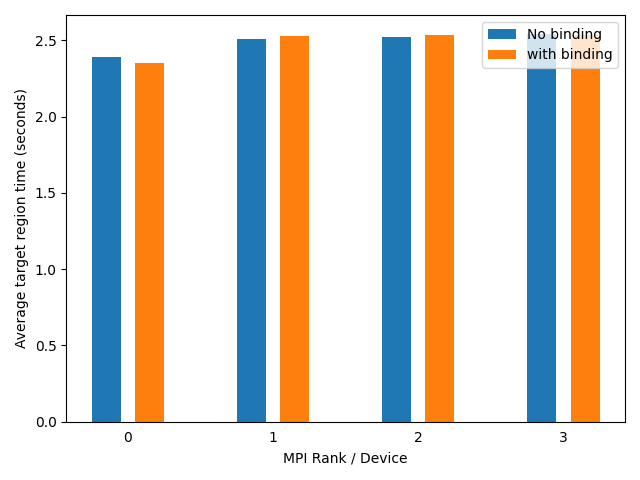
The results of the two runs are shown in the plot below. The runtime of the target region between the two runs does not differ much. The effects of GPU affinity are not visible on JUWELS Booster since the optimal cores to run the MPI ranks on are already selected by Slurm extensions in PSSlurm. Therefore, with no explicit binding the kernel already runs on the optimal configuration.
This table shows the mapping between tasks and executing units:
| MPI Rank | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| CPU / NUMA domain (no binding) | 0 / 3 | 12 / 1 | 24 / 5 | 36 / 7 |
| CPU / NUMA domain (with binding) | 1 / 3 | 24 / 1 | 49 / 5 | 72 / 7 |
| Device / NUMA domain | 0 / 3 | 1 / 1 | 2 / 5 | 3 / 7 |
