Performance Optimisation and Productivity
A Centre of Excellence in HPC
GPU affinity on one node with 4 GPUs (MN5)
This experiment shows the difference in runtimes is shown between running with default CPU binding and manual binding to NUMA domains.
Launch configuration
Both runs were launched with 4 MPI tasks, filling up one node with 4 GPUs. Each task offloaded to one GPU.
The run including binding the tasks to the correct NUMA domains was launched as follows:
srun --cpu-bind=map_cpu:0,20,40,60 ./kernel.exe 8000000000
System
MareNostrum 5 ACC node
- CPU: 2x Intel Xeon Platinum 8460Y+ 40C 2.3GHz (80 cores per node, 2 threads per core)
- GPU: 4x NVIDIA Hopper H100 64GB HBM2
- 2 NUMA domains (one for each socket)
- GPU NUMA affinity:
| GPU | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| NUMA domain | 0 | 0 | 1 | 1 |
Results
The results of the two runs are shown in the plot below. The runtime of the target region differs for MPI ranks 1 and 2. This happens since with no CPU binding the processes are executed on cores that are on a different socket than the GPU that they are using. This leads to a lower bandwidth and a higher latency.
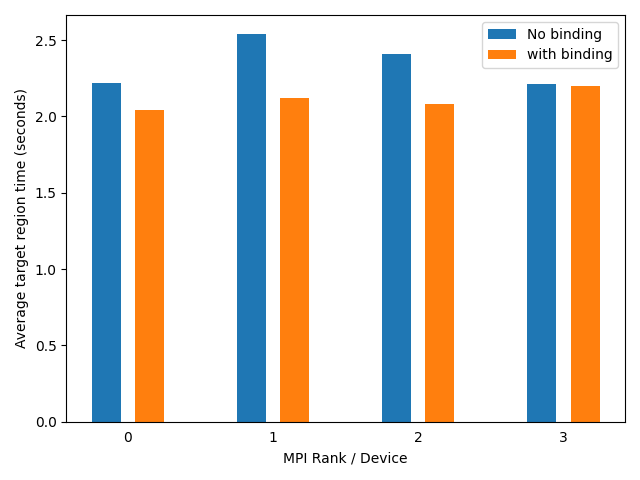
This table shows the mapping between tasks and executing units:
| MPI Rank | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| CPU / NUMA domain (no binding) | 0 / 0 | 40 / 1 | 1 / 0 | 41 / 1 |
| CPU / NUMA domain (with binding) | 0 / 0 | 20 / 0 | 40 / 1 | 60 / 1 |
| Device / NUMA domain | 0 / 0 | 1 / 0 | 2 / 1 | 3 / 1 |
