Performance Optimisation and Productivity
GPU-kernel analysis of GPU-aware MPI version
Setup
The analysis of the GPU-aware MPI version of the matrix multiplication kernel was performed on the Leonardo booster system at CINECA. Each node operates 4 NVIDIA A100 GPUs. Details on the architecture of a compute node of Leonardo booster can be found further below. For all experiments Open MPI 4.1.6, configured with UCX and HCOLL of NVIDIA hpcx 2.18.1.
Experiment across 2 nodes
In the following, all times are presented in milliseconds, Total is the sum of all specified operation times, averaged among processes, and Runtime is the total runtime of the application.
Comparing the total runtime of the GPU-aware MPI version with the GPU-unaware MPI version, the GPU-aware version achieves a speedup of over 2x.
While more time is spent transferring time from the GPU to the host (D2H), less time is spent transferring data from the host to the GPU (H2D).
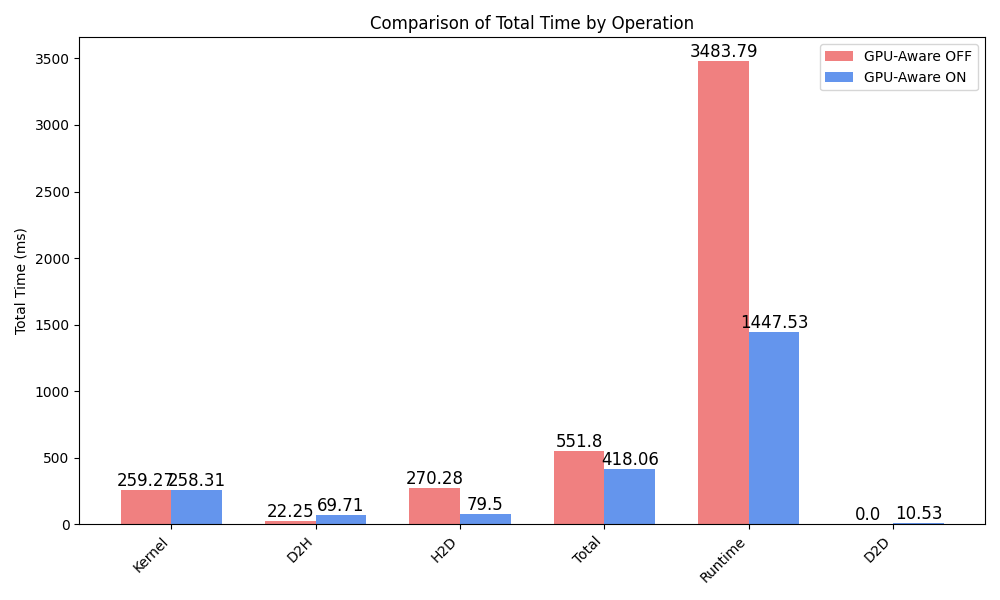
Category Operation Avg_Total_Time Avg_Min_Time Avg_Max_Time Instances_per_Process
CUDA_KERNEL Kernel 258.30815 255.3486 259.5878 5.0
MEMORY_OPER D2D 10.53345 3.7839 20.5761 10.833333333333334
MEMORY_OPER D2H 69.71385 7.2433 133.0604 1322.0
MEMORY_OPER H2D 79.49983333333334 23.5555 209.179 1920.3333333333333
Total Total 418.05528333333336 289.93129999999996 622.4033 3258.1666666666665
REGION Runtime 1447.529000 0.0000 0.0000 1.000000
Regarding MPI, MPI_Bcast is about 9x faster while MPI_Gather and MPI_Scatter are less than 2x slower.
There are different reasons for this behavior.
On the one hand, MPI operations may take longer as the implicit data transfers are now part of the MPI operation.
On the other hand, the actual communication time between ranks may be improved by leveraging optimized communication channels between GPUs, such as NVIDIA’s NVLink.
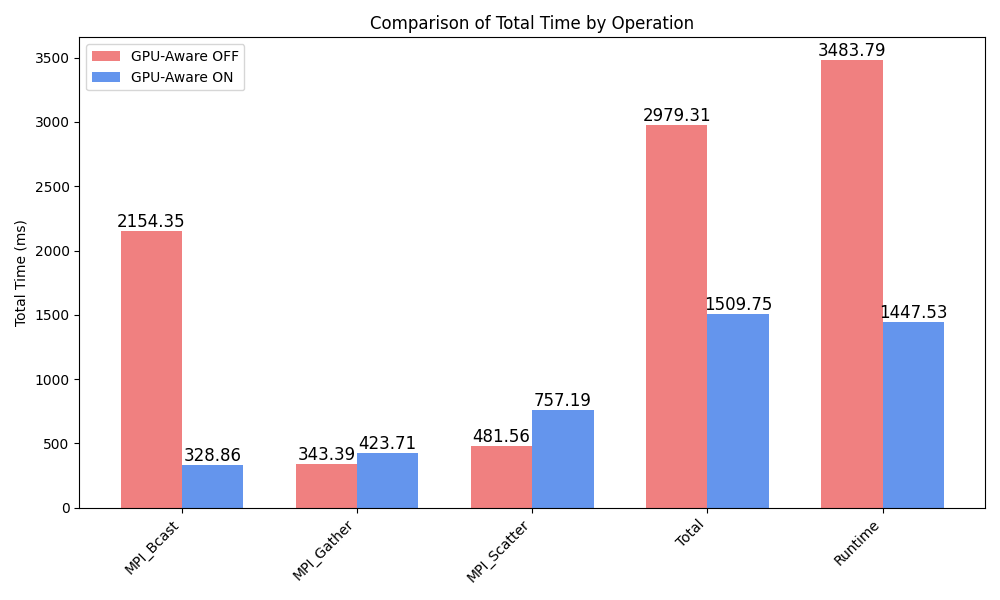
Category Operation Avg_Total_Time Avg_Min_Time Avg_Max_Time Instances_per_Process
collectives MPI_Bcast 328.85635 177.4334 520.754 5.0
collectives MPI_Gather 423.70959999999997 45.5012 826.8254 5.0
collectives MPI_Scatter 757.18815 177.1052 1261.6396 5.0
Total Total 1509.7540999999999 400.0398 2609.219 15.0
REGION Runtime 1447.529000 0.0000 0.0000 1.000000
Scalability
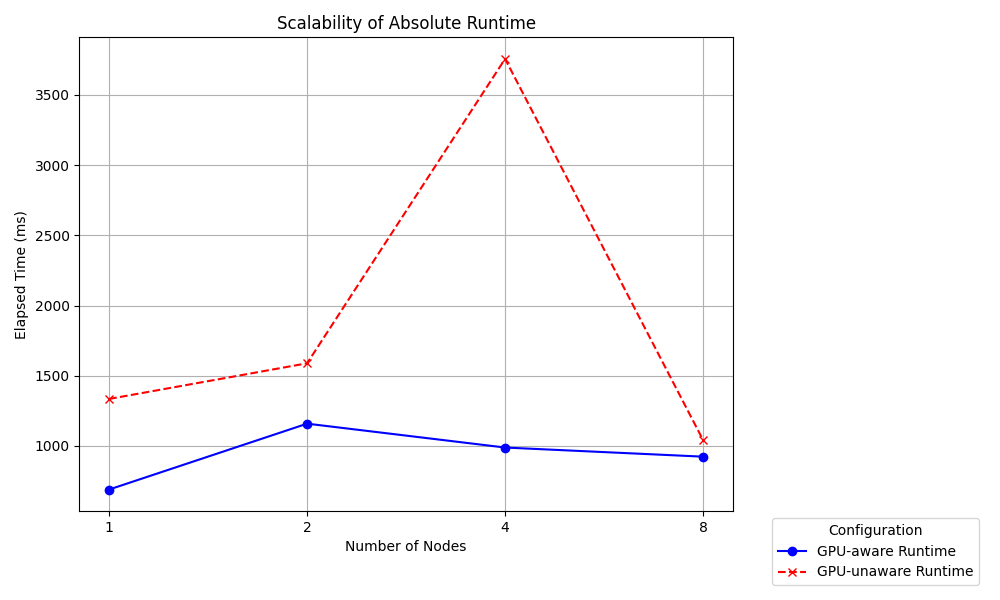
The first figure below shows the absolute runtime of both configurations (GPU-unaware vs GPU-aware) for executions with 1 to 8 nodes.
For 1 node a speedup of 2x is achieved by using GPU-aware MPI. Here all GPUs can directly communicate with each other over the high-bandwidth NVLink connection.
The speedup is slightly reduced for the execution across 2 nodes. GPUs of different nodes must communicate over InfiBand which offers reduced bandwidth compared NVLink.
Further investigation of the trace for 4 nodes reveals MPI_Bcast and MPI_Scatter as the cause for the increased runtime of the GPU-unaware execution.
For 8 nodes, both configurations seem to converge. The host to device transfer of matrix B takes less time, as the chunk size each process handles is further reduced. Similarly the device to host transfer of matrix C takes less time.
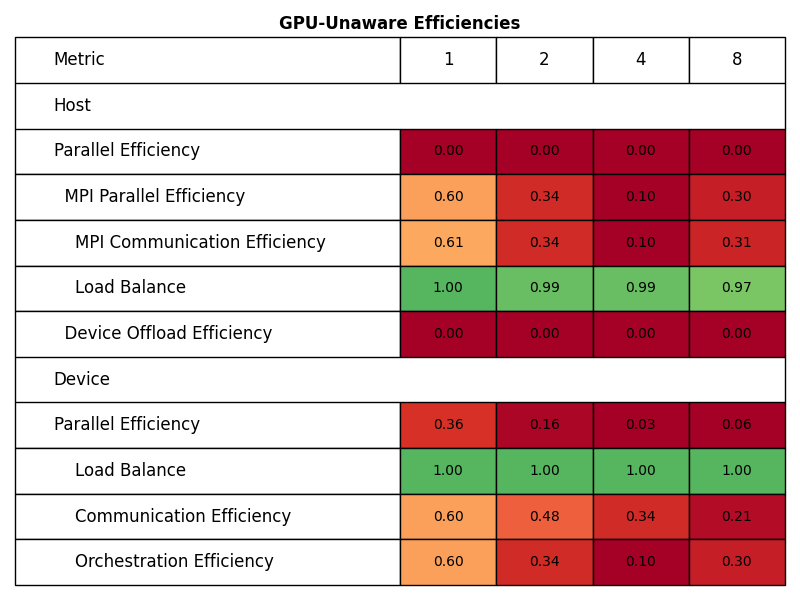
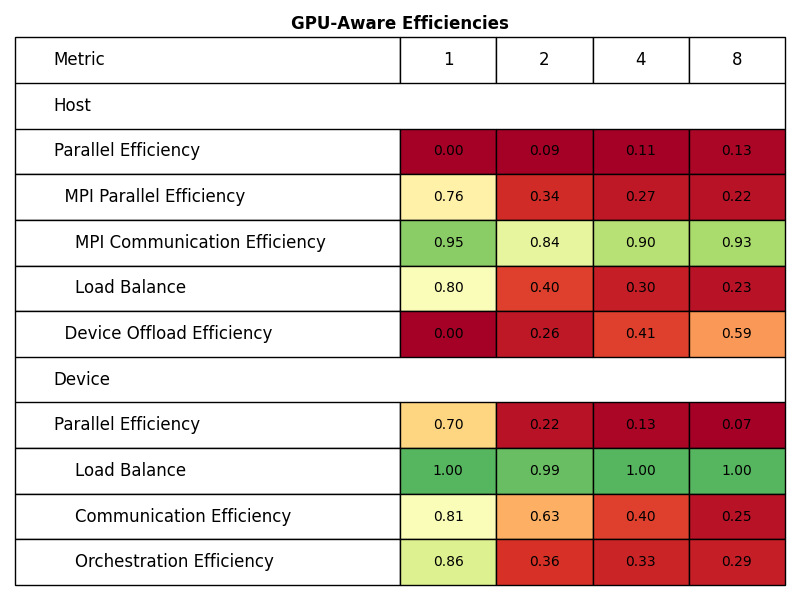
The following two figures show the POP metrics as reported by TALP v3.6.0-beta1 for both configurations for executions with 1 to 8 nodes.
The decreasing Device Communication Efficiency of the GPU-aware execution can be explained by proportionally more data being transferred between GPUs across nodes than among GPUs within a node.
Inter-node GPU-to-GPU transfers involve data transfers between host and device even for GPU-aware MPI communication, therefore the Device Communication becomes less efficient with an increasing number of nodes.
Node architecture
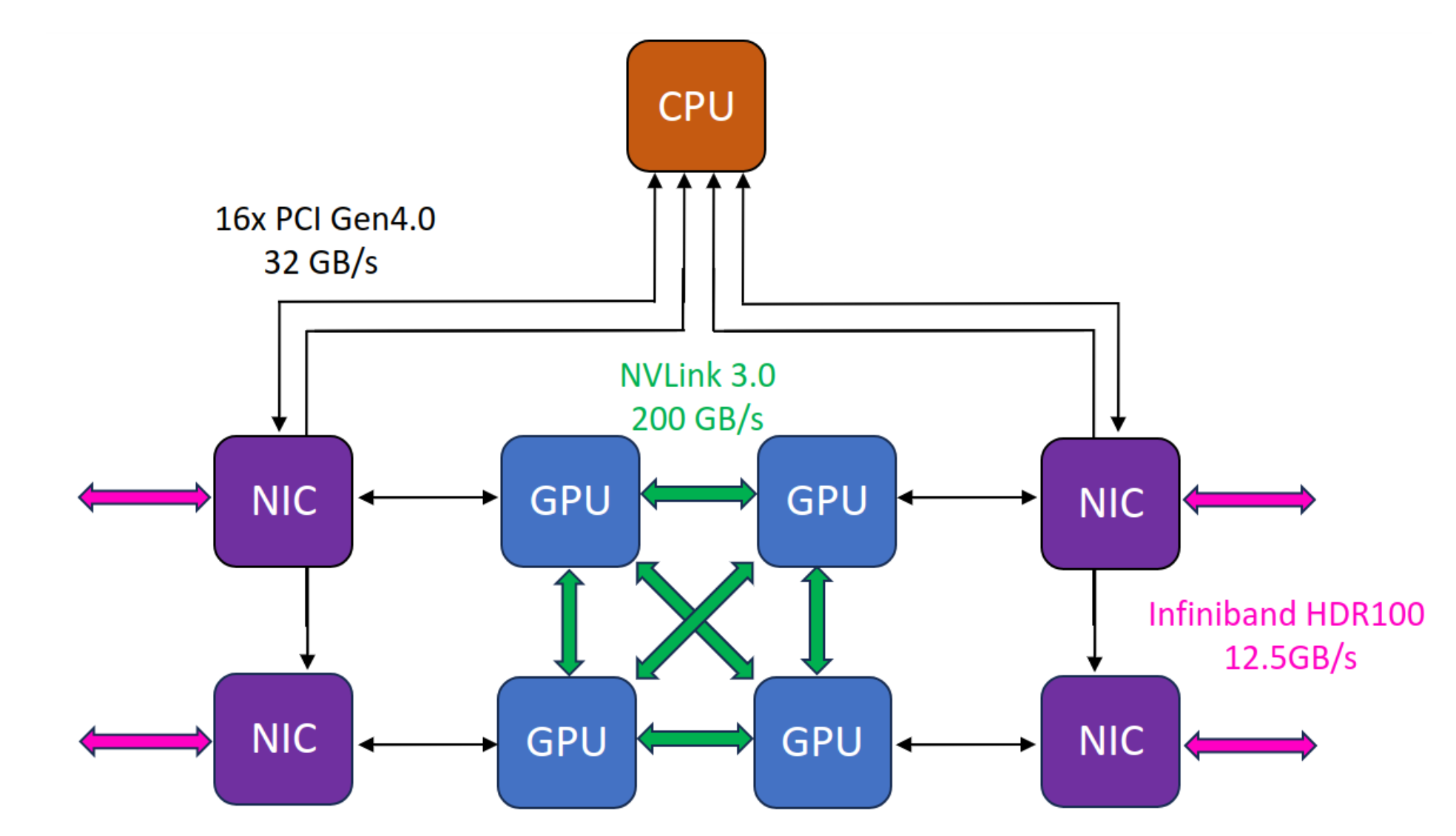
The figure below depicts the network architecture of a GPU node on Leonardo.
The CPU is connected to each GPU via PCIe 4.0, offering 32 GB/s bandwidth per CPU-GPU communication.
All GPUs of a node a are directly connected with each other via NVLink 3.0, providing 200 GB/s bidirectional bandwidth per GPU pair.
Multi-node communication is enabled via InfiBand HDR100 NICs, allowing 12.5 GB/s bandwidth between GPUs of two different nodes.
Additionally, NVIDIA GPUDirect RDMA is enabled, allowing direct GPU-to-GPU communication between nodes, without involvement of the CPU.