Performance Optimisation and Productivity
A Centre of Excellence in HPC
GPU-kernel analysis of GPU-unaware MPI version
The analysis of the GPU-unaware MPI version of the matrix multiplication kernel was performed on the Leonardo booster system at CINECA using 2 nodes operating 4 NVIDIA A100 GPUs each.
Utilizing NVIDIA Nsight Systems, we can see that about 8% of the total runtime is spent transferring data between host and GPU.
In the following, all times are presented in milliseconds, Total is the sum of all specified operation times, averaged among processes, and Runtime is the total runtime of the application.
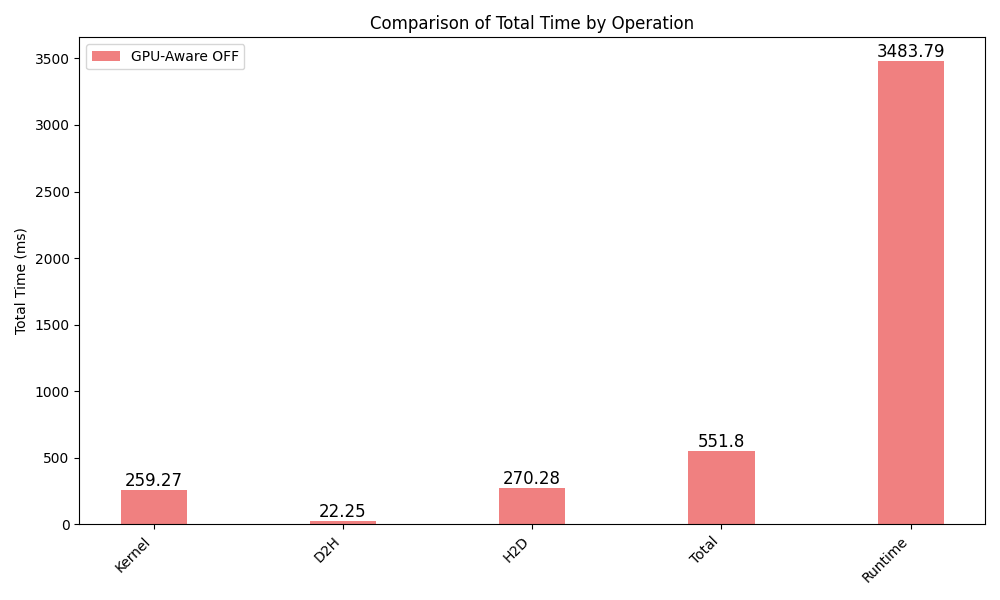
Category Operation Avg_Total_Time Min_Total_Time Max_Total_Time Instances_per_Process
CUDA_KERNEL Kernel 259.2696625 259.023 259.5687 5.0
MEMORY_OPER D2H 22.251375 15.8982 28.8639 5.0
MEMORY_OPER H2D 270.2771 229.878 332.1818 10.0
Total Total 551.7981374999999 504.7992 620.6143999999999 20.0
REGION Runtime 3483.788000 0.0000 0.0000 1.0
The kernel execution (~7%) and MPI communication (~85%) account for the remaining time.
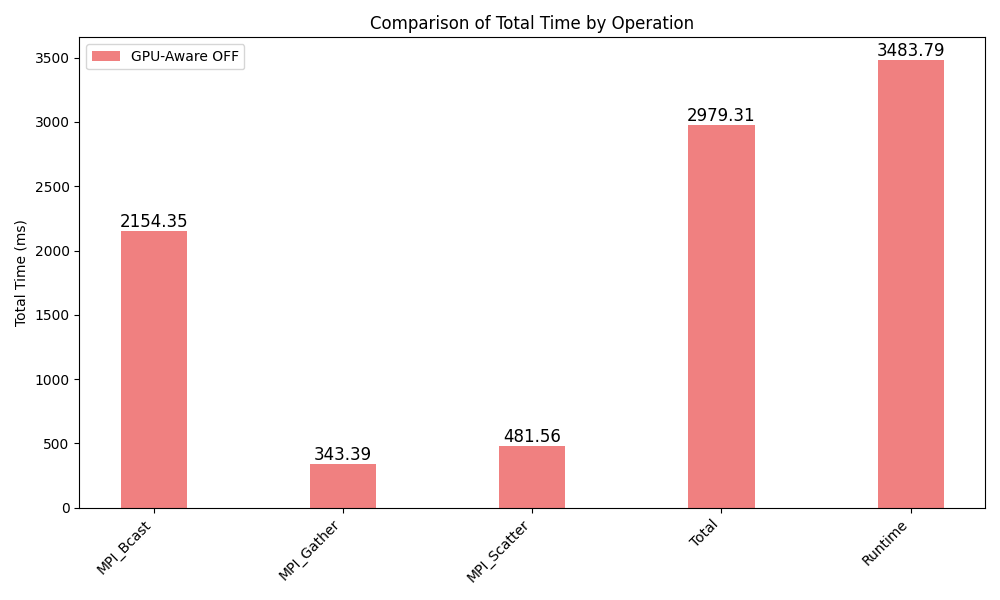
Category Operation Avg_Total_Time Min_Total_Time Max_Total_Time Instances_per_Process
collectives MPI_Bcast 2154.35295 2111.833 2228.5846 5.0
collectives MPI_Gather 343.3941 106.0522 678.7161 5.0
collectives MPI_Scatter 481.56425 161.6287 856.1543 5.0
Total Total 2979.3113 2379.5139000000004 3763.4550000000004 15.0
REGION Runtime 3483.788000 0.0000 0.0000 1.0
