Performance Optimisation and Productivity
JuKKR-kloop openmp version analysis
Environment
All measurements have been performed on one node of the CLAIX-2018 cluster of RWTH Aachen University. A single node is a two-socket system featuring Intel Skylake Platinum 8160 CPUs each. One CPU has 24 cores running with a base frequency of 2.1 Ghz. SubNUMAClustering is enabled which means that there are 4 NUMA domains each with 12 cores in total. The OpenMP threads were pinned to CPU cores of one NUMA domain in a close fashion using the following environment variables:
export OMP_PLACES=cores
export OMP_PROC_BIND=close
Scalability
The openmp version of the k-points integration loop shows strong scalability with an increasing number of OpenMP threads as shown in the figure below:
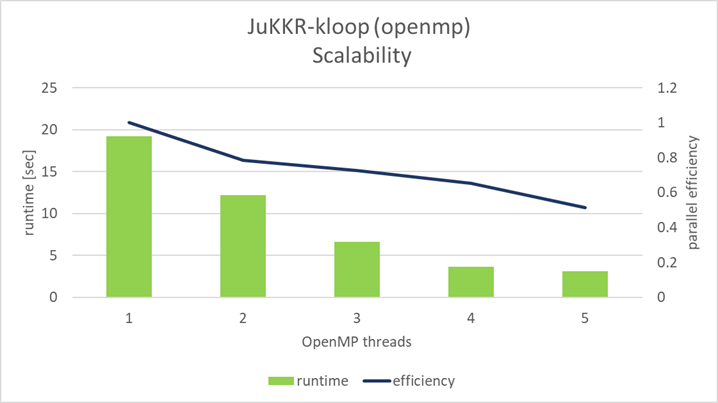
When using 2 OpenMP threads the parallel efficiency is now at 78% compared to 53% in the original master version. Filling the whole NUMA domain with threads still results in a parallel efficiency of 51%. This scalability is still not optimal as there is quite a lot of room for improvement. However, compared to the original master version of the kernel the scalability is much better. In fact the openmp version is 6x faster than the original master version.
Efficiencies
We collected additive hybrid POP efficiency metrics which are shown in the table below:
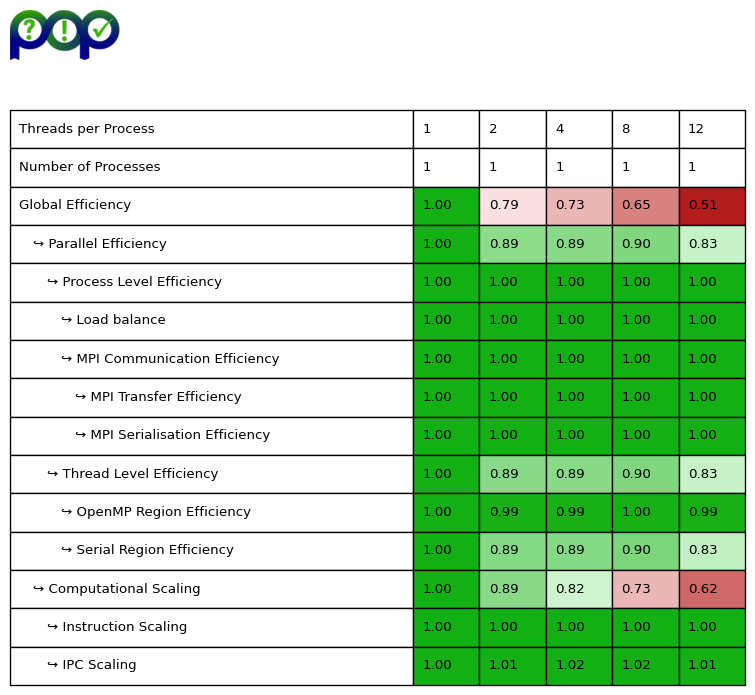
First the Global Efficiency matches with the parallel efficiency from the strong scaling measurements. Furthermore, the POP metrics reveal how the openmp version of the kernel has improved the original master version.
For the master version the Serial Region Efficiency decreased down to 29% when using 12 OpenMP threads. For the openmp version the Serial Region Efficiency improved significantly to 83% which is considered good. In the openmp version of the kernel the k-point integration loop is parallelized using OpenMP worksharing. So now the computation of the matrix \(M_k\) is not only done by the master thread but each OpenMP thread computes a certain number of matrices according to the distribution of k-point loop iterations. This means the time that the application runs in serial on the master thread is significantly reduced so that the Serial Region Efficiency improves. The remaining serial parts of the miniapp are the input/output operations at the start and the end of the miniapp which we did not exclude from our measurements.
The Computational Scalability is only at 62% for the improved openmp version of the kernel. However, this is only caused by the Frequency Scaling which again can be related to Intel Turbo Boost technology.
The IPC Scaling is now optimal which was not the case in original master version of the kernel. In the improved openmp version the LU decomposition of matrices \(M_k\) are each done in serial by a single thread. As the outer k-point loop is parallelized with OpenMP worksharing multiple threads compute multiple LU decompositions concurrently. However, as each thread accesses the data elements of matrix \(M_k\) exclusively we avoid False-Sharing effects and therefore save unnecessary data transfers between caches of different CPU cores. As a result the number of CPU cycles stays constant for each thread even when scaling up the number of OpenMP thread used to execute the kernel. All in all the IPC stays constant as well and so we see a optimal IPC Scaling.
