Performance Optimisation and Productivity
omp-critical experiments
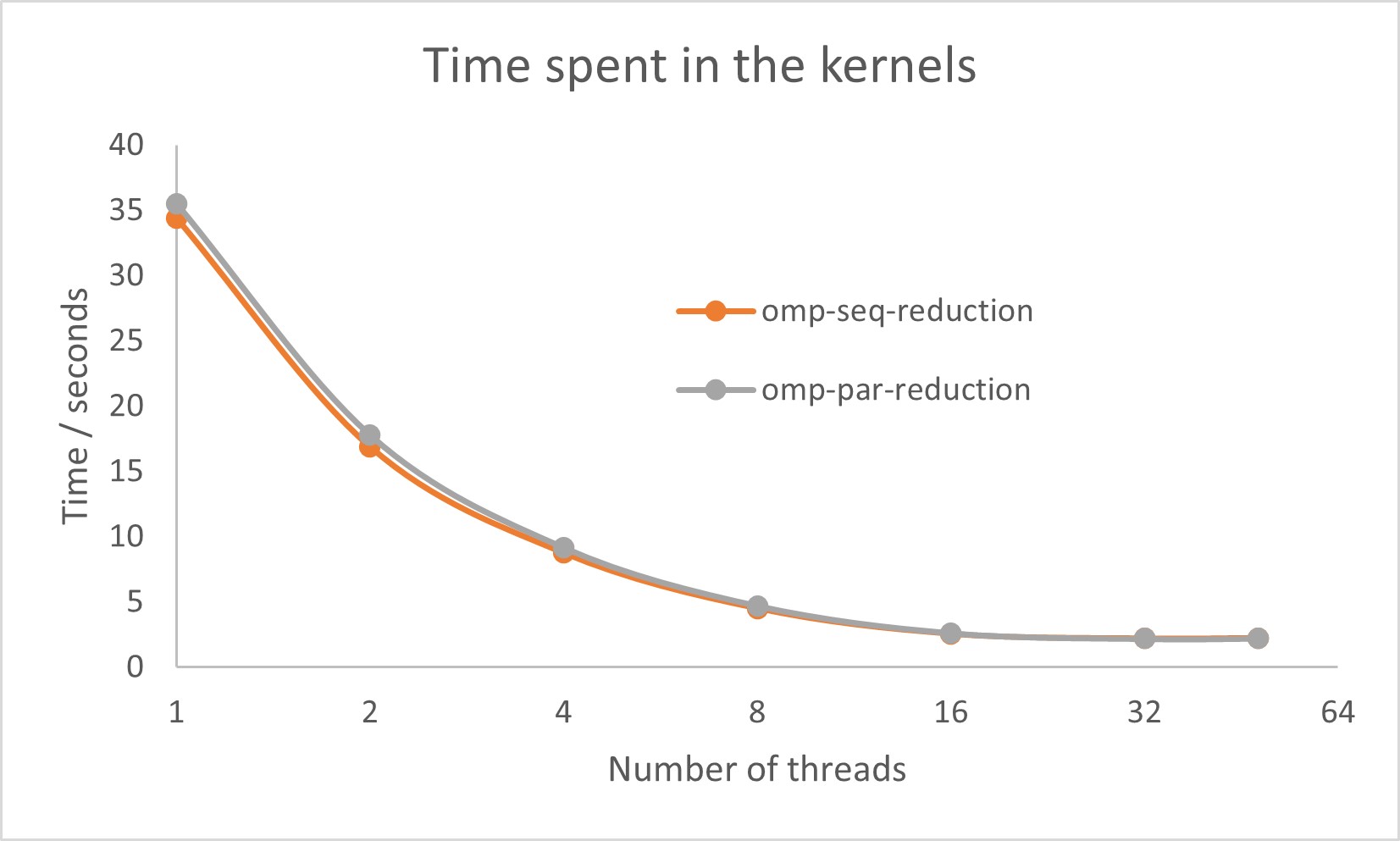
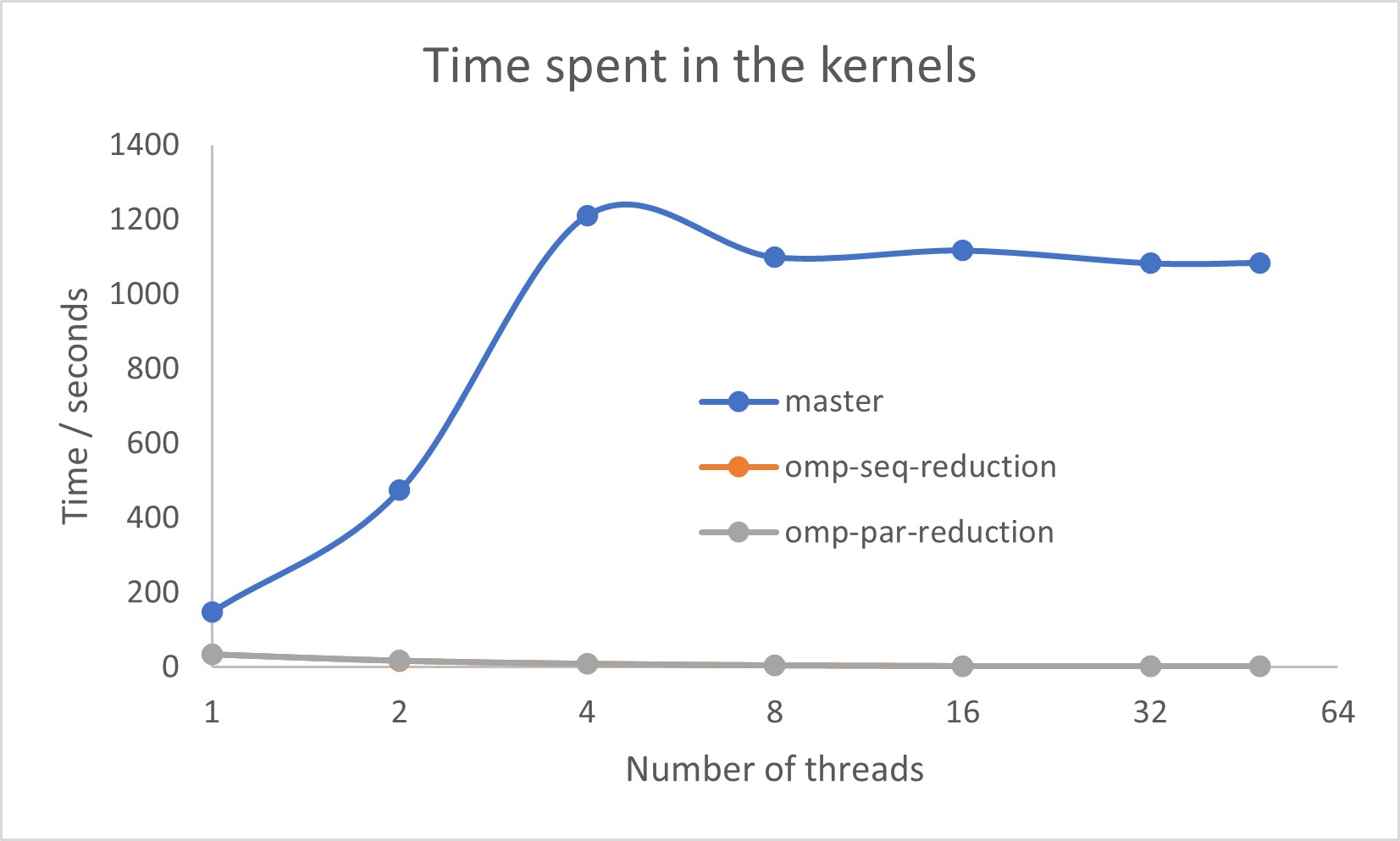
The omp-seq-reduction and omp-par-reduction codes were run on a single 48-core node of MareNostrum-4 at Barcelona Supercomputing Center for a range of thread counts from 1 to 48 and the results compared to those of the original omp-master code. The problem size in all cases was specified by Ni=500, Nj=500, Nk=500 and Nt = 20. The run times and the average IPC (Instructions Per Cycle) values for all three versions are shown here.
 |
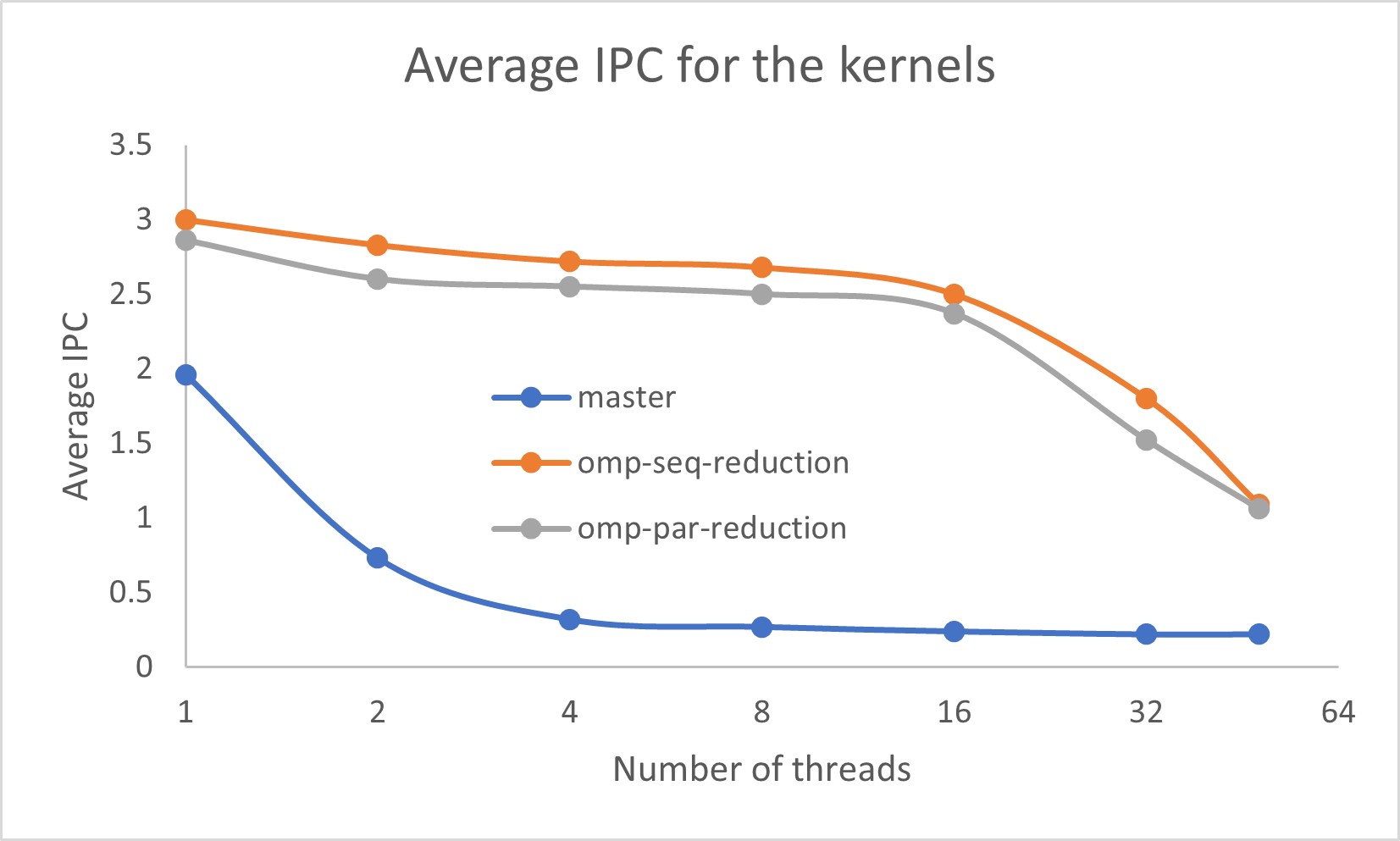 |
Clearly, the new versions of the code show much better performance and have much better avaerage IPC values, with those for the omp-seq-reduction version being marginally better. In order to compare the run times of the omp-req-reduction and omp-par-reduction kernels, these times are plotted below without the much slower master kernel. The omp-seq-reduction version can now be seen to be slightly faster at the lower thread counts. This may of course vary with details of the simulation.