Performance Optimisation and Productivity
Sam(oa)² Experiment (Chameleon)
Description
The following experiment presents an execution with the Sam(oa)² Chameleon version, as well as comparisons with the OpenMP tasking and, partially, work-sharing versions. Folder scripts/calix/ contains scripts to automatically run the application by specifying most of the configuration. Additionally to execution time, it has flags for creating traces using Extrae or Intel Trace Analyzer. Detailed information on how to run, reproduce and evaluate this experiment can be found in the README file located in the root folder.
Execution Environment
This experiment has been conducted on one compute node of the CLAIX-2018 cluster partition at RWTH Aachen University. Each node is a two-socket system featuring Intel Skylake Platinum 8160 CPUs with 24 cores running at a base frequency of 2.1 GHz. Hyper-Threading is disabled and Sub-NUMA-Clustering (SNC) is enabled. Process pinning and thread binding have been applied to ensure that each thread of the application runs on a separate physical core.
Although the application can scale to a much higher number of compute nodes, processes and threads, we chose this setup to better visualize the effects of the different versions.
Evaluation and Results
For these results, we simulated 60 seconds of the Tohoku tsunami in 2011, using 4 processes per node, each with 11 OpenMP threads to limit the size of the trace and to be able to show the desired effects. The domain decomposition used 16 sections per thread to yield a sufficient degree of over-decomposition. The reasoning behind only choosing 11 threads per process stems from the following facts:
- It has been observed that the execution time for certain workloads is shorter compared to a run that is filling up the complete Skylake compute node
- Chameleon uses an additional communication thread that is bound to the last physical core of the cpuset. Thus, only
n-1cores are left for the work threads.
Trace (OpenMP tasking)
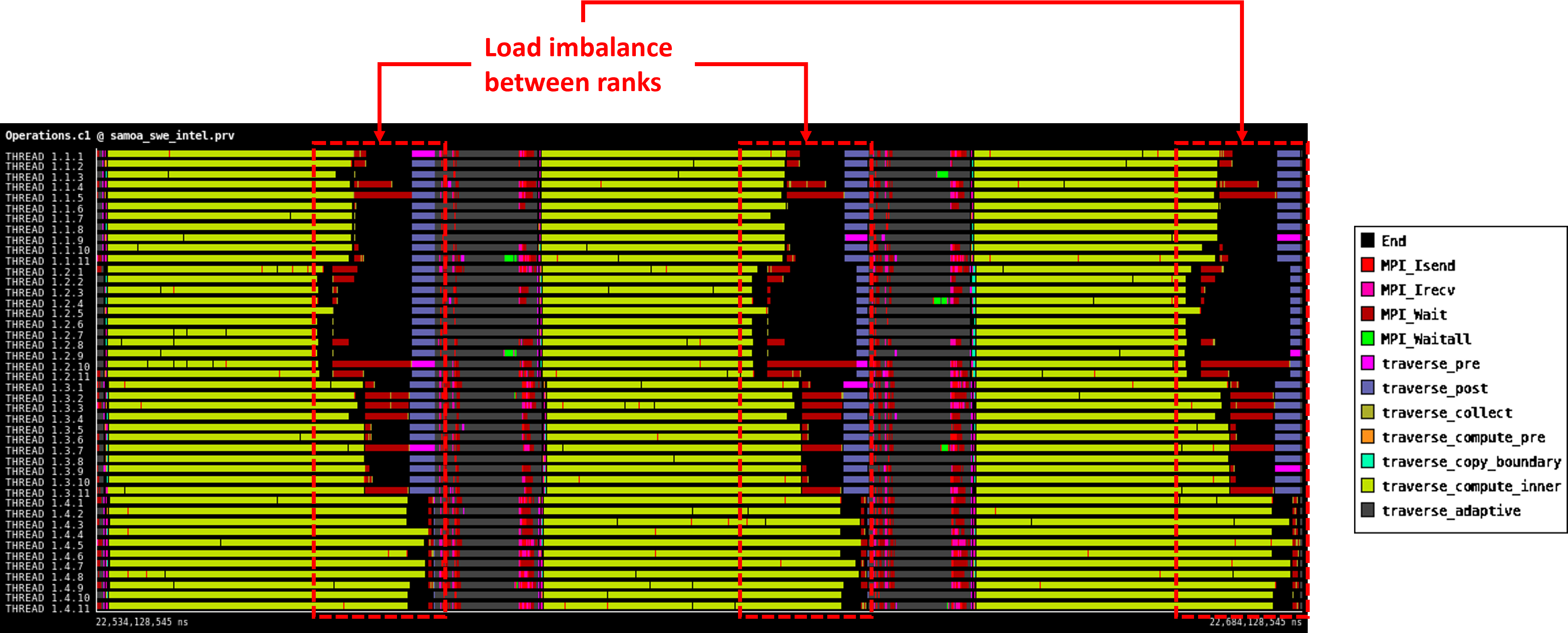
The following trace shows 3 time steps of the main time stepping loop for the version where OpenMP tasks have been used to implement section traversals to allow for load balancing between threads in a process.
 |
|---|
| Trace (OpenMP tasking) |
As illustrated, the load of each process is quite balanced when using OpenMP tasks. However, OpenMP tasking is not able to tackle the imbalance between processes that is still present.
Trace (Chameleon)
The following trace shows the same time steps and the same time scale but here Chameleon tasks have been used to implement section traversals to allow for load balancing, not just between threads in a process but also between processes by temporarily migrating tasks to other processes.
 |
|---|
| Trace (Chameleon) |
As illustrated, the load balance between processes is much better compared to only using OpenMP tasks and the execution time has also been reduced.
Comparison: Execution time
To compare the execution time and to measure the speedup, the same experiment has been conducted simulating 10 minutes of the tsunami scenario, again using 4 processes per node with 11 OpenMP threads each (one process per NUMA domain to avoid runtime variation due to remote memory accesses).
The following table shows the execution times, speedups and the hybrid load balance efficiency (HLBE) for the tested versions.
| Sam(oa)² Version | Execution Time | Speedup (compared to baseline) | Hybrid Load Balance Efficiency (HLBE) |
|---|---|---|---|
| Work-sharing (baseline) | 160.23 sec | 1.0 | 78.95 % |
| OpenMP tasking | 150.10 sec | 1.0674 | 81.93 % |
| Chameleon | 127.27 sec | 1.25897 | 87.10 % |
This shows that Chameleon in this case was able to achieve a speedup of about 1.26x compared to the baseline and about 1.18x compared to the OpenMP tasking version. Additionally, there is a significant increase in the hybrid load balance efficiency compared to both versions. As the work imbalance between sections might increase with longer simulation times, it is also expected to gain even higher speedups with this approach. However, a critical point can be a very small task granularity or general length of a single execution phase, as migrating tasks to foreign processes is not for free and takes some time. There has to be enough work in order to overlap that communication with useful computation.
