Performance Optimisation and Productivity
Communication imbalance in MPI
Usual symptom(s):- Transfer Efficiency: The Transfer Efficiency (TE) measures inefficiencies due to time in data transfer. (more...)
By communication imbalance we refer to the situation where the amount of MPI calls or the message sizes change between processes. Of course the time taken by these communications depends on many factors, of which the number of calls, message sizes are important but also the type of MPI call (blocking or not) or the location of the processes involved in the communication (local within the node or remote).
Communication imbalance is an undesirable pattern but do not constitute a problem by itself. The communication imbalance problem appears when the communication phases in some processes take more time than in others (in average) and all these processes eventually reach a synchronization collective (i.e., barrier) without any intermediate phase compensating the produced imbalance. Arriving the collective at different times will cause some processes will waste their time waiting for others to reach the collective.
Communication- or load- imbalance are sibling patterns. They start the very same behaviour in their executions that will finally paid in the next synchronization phase (if it is not compensated before).
A typical skeleton that exposes the communication imbalance issue might look like:
void main( int argc, char *argv[] ) {
// ...
// Domain decomposition: equally number of elements distributed among ranks
int n_elems; // ... as the result of the domain decomposition
int n_neighs; // ... that happens to be significantly different between MPI ranks
int neighbors[n_neighs]
for (int step = 0; step < N_STEPS; step++) {
// Some code before communication
for (int i = 0; i<n_neighs; i++) MPI_Irecv(..., neighbors[i],...);
for (int i = 0; i<n_neighs; i++) MPI_Send(..., neighbors[i],...);
// Some code before wait
MPI_Waitall(); // waiting for all the receives
for (int i = 0; i<n_elems; i++) {
compute(i); // same amount of computation on each process (balanced)
}
// Some code before synchronization
MPI_Allreduce();
}
// ...
}
The previous pseudo-code shows how the number of MPI_Irecv and MPI_Isend in
communication phase depends on the number of neighbors per rank. After this
communication phase, first comes a computational phase, and right after the
collective MPI_allreduce that will block all processes until completion.
The following figure illustrates the previous example by means of the OpenFOAM toolbox, providing two different semantics: above the sequence of MPI calls, below the useful duration of the computational phases.
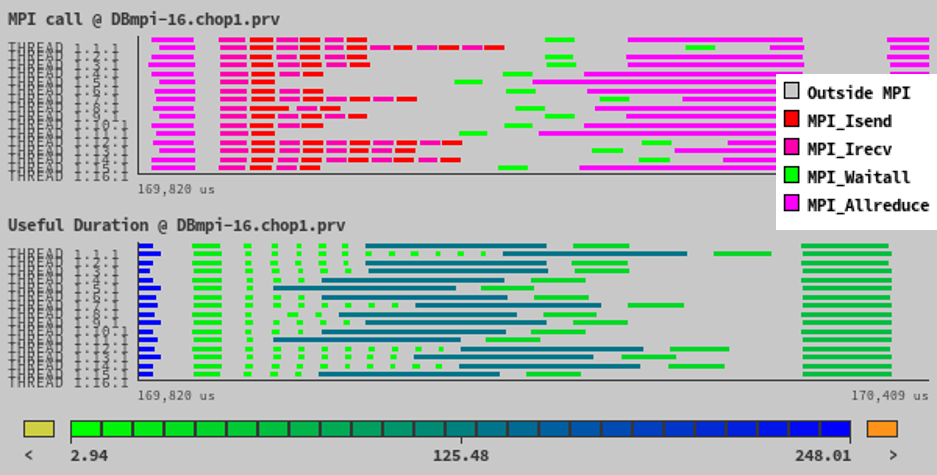
Previous trace shows how each process executes a different number of
MPI_Isends and MPI_Irecvs. The computation after these MPI calls is
actually balanced across processes and the delay introduced at the Isends/Recvs
is propagated. The imbalance originated at the Isend/recv phase is globally
paid much later, at the next collective call: MPI_Allreduce in this case.
The following figure also shows the imbalance effect in the CP2K application. The trace shows the sequence of MPI calls executed by the different threads:
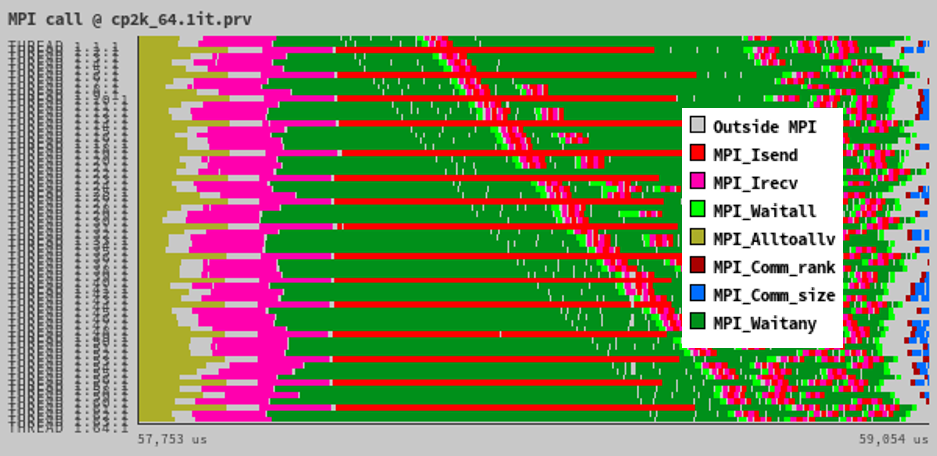
In this case we see how some processes do perform many more Isends/Irecvs than
others following a regular pattern. Processes not performing the large
sequences of Isends/recvs do spend their time waiting at MPI_Waitany calls.
In addition, the imbalance issue is exacerbated by the fact that the
communication pattern results in a serialized pipeline of the communications.
In fact, this serialization effect is even more important than the imbalance
effect shown in that trace.
- When the imbalance is caused by a domain decomposition that generates a different number of neighbours per sub-domain ⇒ Re-consider domain decomposition
