Performance Optimisation and Productivity
Writing unstructured data to linear file formats
Many applications cope with unstructured data, which result in unbalanced data distribution over processes. A simple example for this are particle simulations where particles are moved around between processes over time. So, when the simulation shall write the global state at the end - or in-between, e.g., for a checkpoint - each process will have a different number of particles. This makes it hard to write data efficiently to a file in a contiguous way. The same pattern can also be found, e.g., in applications using unstructured meshes with different number of elements per process.
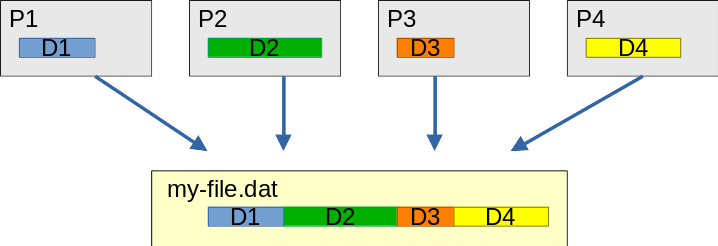
Four processes with different amount of data that are to be written to a contiguous file “my-file.dat”
An often seen but obviously bad approach to cope with this is serialization of the I/O across the processes. Instead offset based parallel I/O should be applied.
Recommended best-practice(s): Related program(s):