Performance Optimisation and Productivity
Avoidable transfers between host and GPU for MPI communication (GPU-Aware MPI)
Pattern addressed: Avoidable transfers between host and GPU for MPI communication (GPU-Unaware MPI)When GPUs perform computation in an MPI program and multiple nodes are involved, data exchange between GPUs across different nodes must still be orchestrated by the host, as MPI generally lacks proper GPU support. This host communication can lead to unnecessary transfers of data between the host and GPU, which can be optimized or completely avoided by using GPU-aware features provided by common MPI libraries. (more...)
In an iterative GPU-accelerated computation, where data is transferred between host and device in each iteration only to be exchanged via MPI, that is without any processing on the host, the transfers between host and device can be avoided by making use of MPI’s GPU-aware feature. Despite not being standardized, the two commonly used MPI implementations, OpenMPI and MPICH, and their derivatives support GPU-aware communication.
Avoiding transfers between host and GPU with GPU-aware MPI
The GPU-aware feature allows omitting explicit data transfers between host and device by directly using device buffers in communication operations. The snippet below shows the usage of this feature by moving the explicit transfers outside of the iterative process to a pre- and post-step. Note that due to the asynchronous nature of kernel launches, the MPI operation executed after the kernel and the kernel itself may run concurrently on the device, dependent on the internal implementation of the MPI operation. Hence, kernel completion must be ensured before a successive MPI operation (here MPI_Gather) by synchronizing the device or stream of the kernel. A blocking GPU-aware MPI call already ensures completion of the communication before the call returns. Therefore, no additional explicit synchronization between the MPI_Bcast and kernel launch is necessary.
cudaMalloc(&device_buf, size);
if (rank == root) /* Data needs to reside on GPU at the root for initial exchange */
cudaMemcpy(device_buf, host_buf, size, cudaMemcpyHostToDevice);
for (int i = 0; i < NUM_ITERATIONS; i++) {
MPI_Bcast(device_buf, ...);
kernel<<<...>>>(device_buf);
cudaDeviceSynchronize();
MPI_Gather(device_buf, ...);
}
cudaMemcpy(host_buf, device_buf, size, cudaMemcpyDeviceToHost);
Performance impact
The possible performance benefit by using GPU-aware MPI in comparison to explicit memory transfers between host and device depends on several factors:
- MPI implementation: Regardless of GPU-aware communication, different MPI libraries perform different optimizations. E.g. by providing different algorithms for a single collective, which are chosen dependent on the execution environment. The same holds for GPU-aware communication, where different MPI libraries may perform different optimization strategies.
- MPI operation: To which degree the MPI library is able to optimize the memory transfer further depends on the specific MPI operation. E.g. complex collectives may require computation on the host, leading to additional transfers between host and device.
- Hardware support:
- GPU-NIC connection: Completely avoiding the CPU requires a direct connection between the GPU and NIC when performing inter-node communication. This can be achieved by technologies like NVIDIA’s GPUDirect RDMA.
- GPU-to-GPU connection: If there is no direct connection between the GPUs, or if the route includes the CPU, the MPI library may choose to fall back to host-to-host communication
The following observations are therefore specific to that specific application and execution environment. For more information on the application and execution environment visit the linked experiment page.
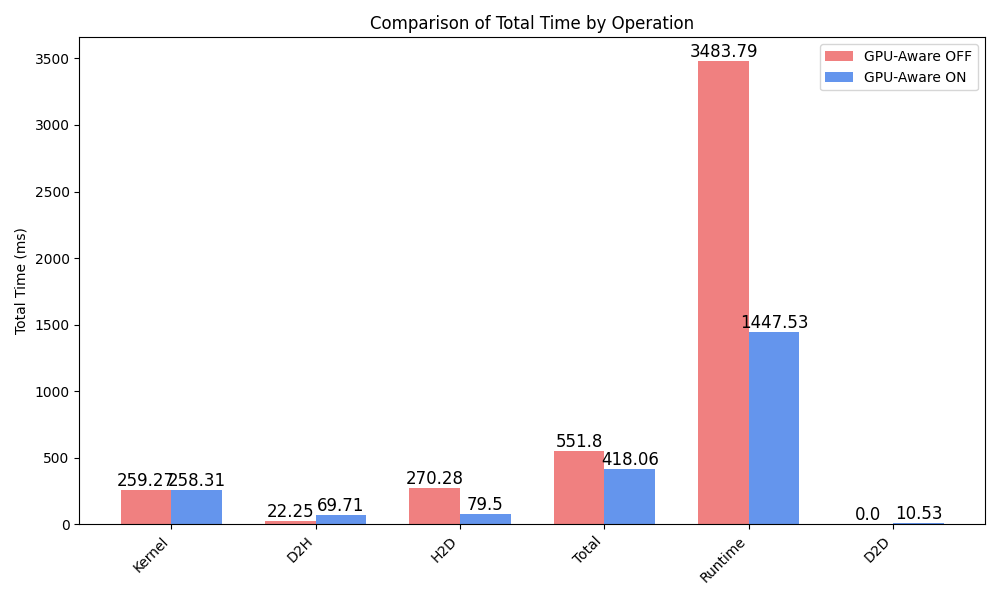
The figure below shows the impact of the GPU-aware MPI feature for an execution with 8 processes across two nodes, each maintaining one GPU. The kernel execution itself is not influenced. About 3x more time is spent in device to host (D2H) transfers when using GPU-aware MPI communication. However, host to device transfers can be reduced by a factor of 3. Furthermore, time is spent performing direct device to device (D2D), ofthen named P2P in NVIDIA tools, transfers. In total, the GPU-aware execution spends about 50% less time transferring memory (D2H, H2D and D2D).
Visibility in traces
The difference between GPU-aware MPI disabled and enabled can also be observed in the two figures below, each showing an NVIDIA Nsight Systems trace of a single iteration. The first trace shows the original version that does not employ GPU-aware MPI, showing the explicit memory copies before and after the kernel execution. In the GPU-unaware case, the single interation takes about 420ms.

The second trace shows the GPU-aware MPI version, revealing the internal usage of CUDA inside MPI operations. It is scaled to show the same time frame as the GPU-unaware trace. In the GPU-aware case, the single iteration is marked by the red bars and takes about 235ms.

The red parts in the CUDA HW lines depict device to device transfers, while the magenta parts are device to host and the turquoise host to device transfers. It can be observed that MPI_Scatter and MPI_Bcast make use of D2D transfers, while MPI_Gather does not. Whether the MPI operation may leverage D2D communication, depends on the MPI library’s implementation, the specific MPI operation and HW environment (e.g. if the communicating GPUs are connected via NVLink).
POP Metrics
The impact is also observable through the POP metrics.
The table below shows the metrics for the execution above (2 nodes, each 4 GPUs) as reported by TALP v3.6.0-beta1.
The Host metrics reveal an improved Communication and Device Offload Efficiency, while the Device metrics show improved Communication Efficiency.
The improved Host Communication Efficiency is the result of optimized collectives in the GPU-aware execution (there is an 9x speedup for MPI_Bcast, see the experiment page).
The Device Offload Efficiency is higher since less time is spent on the the host actively waiting for the GPU.
The increased Device Communication Efficiency stems from the reduced time spent in memory transfers between host and device.
The reduced MPI Load Balance is also a result of the MPI library using a different algorithms for the collectives in the GPU-aware execution.
| Category | GPU-aware OFF | GPU-aware ON |
|---|---|---|
| Name | kernel loop | kernel loop |
| Elapsed Time | 1.68 s | 1.15 s |
| Host | ||
| Parallel Efficiency | 0.00 | 0.08 |
| - MPI Parallel Efficiency | 0.32 | 0.34 |
| - Communication Efficiency | 0.32 | 0.85 |
| - Load Balance | 1.00 | 0.40 |
| - In | 1.00 | 0.50 |
| - Out | 1.00 | 0.81 |
| - Device Offload Efficiency | 0.00 | 0.25 |
| NVIDIA Device | ||
| Parallel Efficiency | 0.15 | 0.22 |
| - Load Balance | 1.00 | 1.00 |
| - Communication Efficiency | 0.49 | 0.62 |
| - Orchestration Efficiency | 0.31 | 0.36 |
Independent of the specific application and MPI operations used, the metric that should be influenced positively by leveraging GPU-aware MPI is the Device Communication Efficiency since it directly reflects the time spent in transfers between host and device. Visit the experiment page to see how the metrics scale for different number of GPUs and nodes.
GPU-aware MPI support in MPI libraries
The GPU-aware feature is supported by Open MPI and MPICH, and most of their derivatives. With a few exceptions, such as specific nonblocking collectives, most communication functions are supported for NVIDIA GPUs when utilizing UCX. Support for AMD GPUs when using UCX is experimental. MPICH also has experimental support for Intel GPUs.
The table below shows the support for different MPI implementations
| MPI Implementation | CUDA-Aware Support | Supported MPI Functions (GPU memory) | Unsupported MPI Functions (GPU memory) | Transport Layer | GPU Support Since Version | Supported GPU Architectures | Notes |
|---|---|---|---|---|---|---|---|
| OpenMPI | Yes | P2P, blocking collectives | nonblocking collectives | UCX, CUDA IPC | v1.7.0 (basic), v4.0.0+ (UCX matured) | NVIDIA (CUDA), AMD (ROCm, experimental via UCX) | UCX strongly recommended; ROCm support is not officially stable |
| MPICH (with UCX) | Partial | P2P, some blocking collectives | Many collectives, nonblocking collectives | UCX, OFI (libfabric) | v4.0.0 (2022, UCX pointer support) | NVIDIA (CUDA via UCX), AMD (ROCm), Intel (Level Zero - experimental) | GPU support highly backend-dependent; not fully stable yet |
| Intel MPI | Yes | All? | None? | UCX, Intel OFI | v2021.1+ (CUDA), v2023+ (Intel Level Zero) | NVIDIA (CUDA), Intel GPUs (Level Zero) | I_MPI_OFFLOAD=1 enables GPU memory handling |
| MVAPICH2-GDR | Yes | P2P, blocking collectives | None (for NVIDIA GPUs) | Infiniband (GDR), SHMEM | v2.0a (basic), v2.2+ (collectives), v2.3.x (IPC, managed mem) | NVIDIA (CUDA) only | Optimized for NVIDIA + IB; supports CUDA IPC, managed mem, GPUDirect RDMA |
| Cray MPI (HPE) | Yes | P2P, blocking collectives | May lack some exotic or non-standard variants | Slingshot, Aries | CLE 6+ / Cray MPI 7.7+ | NVIDIA (CUDA), AMD (system dependent) | Integrated with Cray environments; CUDA support stable |
Recommended in program(s): GPU Kernel GPU-aware MPI ·
Implemented in program(s): GPU Kernel GPU-aware MPI ·
