Performance Optimisation and Productivity
CalculiX-solver trace analysis of OpenMP version
Pattern comparison
The following figure shows a comparison between a trace of the pthread version and the OpenMP version of the CalculiX-solver kernel.
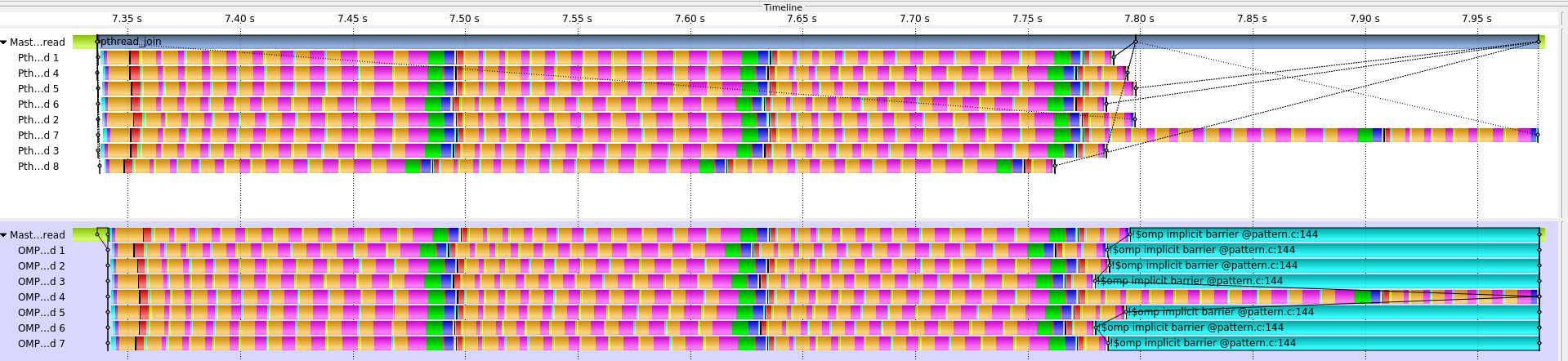 |
|---|
| ScoreP trace comparison of the CalculiX-solver kernel pthread version (top) and the OpenMP version (bottom). |
In both cases the same non-symmetric linear system is solved using GMRES. The OpenMP version reveals the same pattern “Load imbalance due to computational complexity unknown a priori” as the original pthread version. In both traces most of the threads are finished with the GMRES procedure after 31 or 32 iterations. However, one thread needs to perform 46 iterations until its solution converges resulting in a significant load imbalance.
Implemented best practice
In order to improve this load imbalance the OpenMP version implements the best-practice “Conditional nested tasks within an unbalanced phase”. Additionally, the same approach is also implemented using parallel regions for demonstration purposes. (see “Conditional nested parallel region within an unbalanced phase”).
For both approaches several subroutines of the GMRES solver are parallelized using a nested parallelism either in form of tasks or parallel regions.
These include the matvec, daxpy, msolve, and dlrcal subroutines.
As soon as one thread is finished with its own computation it signals completion by increasing an atomic counter variable.
Each time the straggling thread encounters one of the mentioned subroutines it splits its own computation into as many chunks as there are other threads that have already completed their work.
Conditional nested tasks within an unbalanced phase
The result of implementing nested tasks is shown in the following figure.
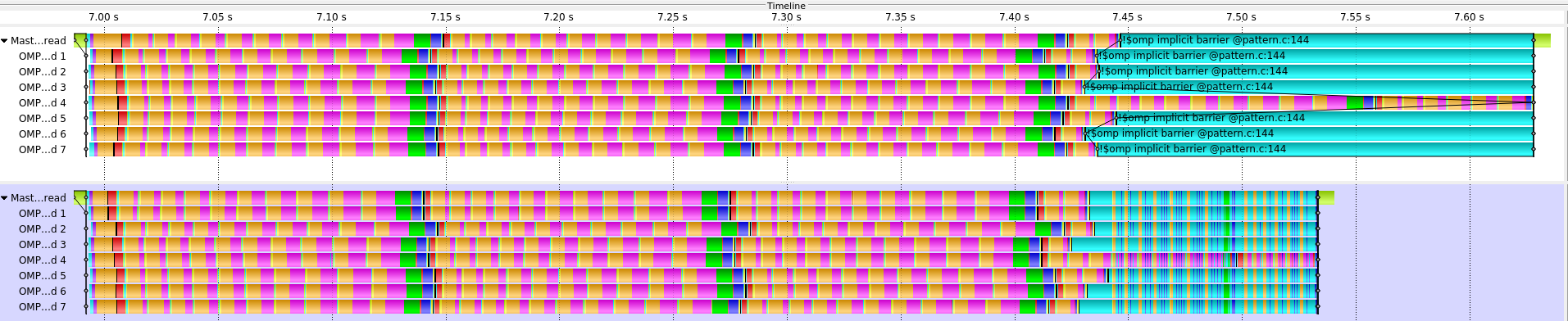 |
|---|
| ScoreP trace comparison of the CalculiX-solver pattern OpenMP version (top) and the implemented best-practice using nested tasks (bottom). |
The trace at the top of the figure shows the original pattern of the OpenMP version of the kernel.
The bottom trace shows the implemented best-practice using nested tasks in the OpenMP version of the kernel.
One can recognize that as soon as the other threads are finished with their workload the straggling thread can accelerate its computation by splitting it into tasks.
These tasks can then be executed by the idling threads as well.
In the original version the straggling thread finishes its computation after 0.643 seconds. In the modified version this thread already finishes after 0.540 seconds. This is a speedup of roughly 1.19. The load-balance efficiency in the modified version is also improved and is now at 88%.
Conditional nested parallel region within an unbalanced phase
The result of implementing nested parallel regions is shown in the following figure.
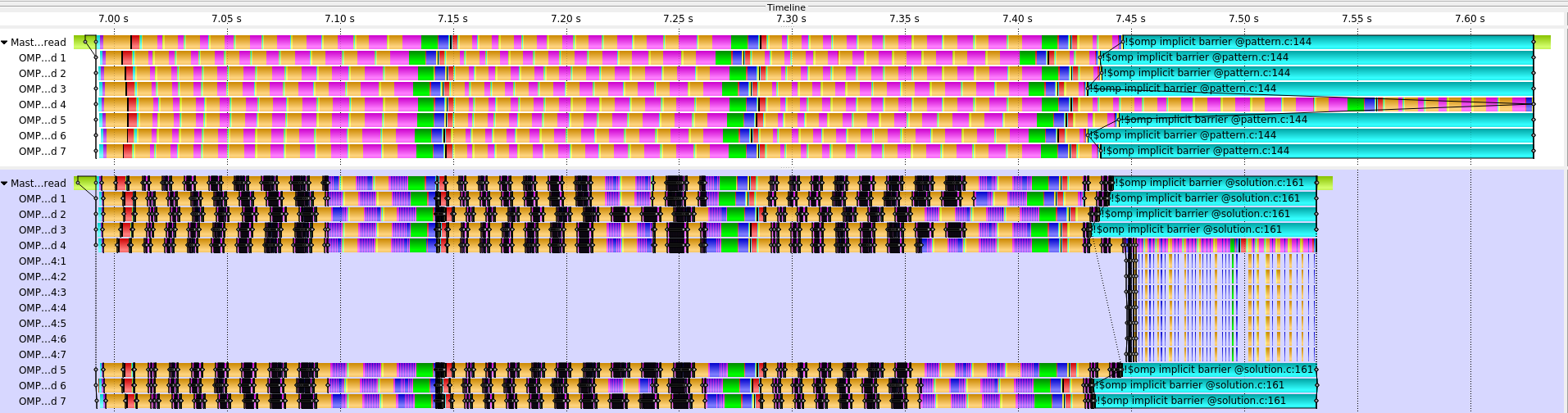 |
|---|
| ScoreP trace comparison of the CalculiX-solver pattern OpenMP version (top) and the implemented best-practice using nested parallel regions (bottom). |
The trace at the top of the figure shows the original pattern of the OpenMP version of the kernel.
The bottom trace shows the implemented best-practice using nested parallel regions in the OpenMP version of the kernel.
One can recognize that as soon as the other threads are finished with their workload the straggling thread can accelerate its computation by executing the nested parallel regions inside the mentioned subroutines with multiple threads that run on the idling cpu cores.
By restricting the kernel excution to 8 physical cores these additional threads will then be scheduled on one of the idling cpu cores. Ideally this should be handled by the OpenMP runtime. But for now we can only simulate this behavior by pinning the application to specific physical cores.
In the original version the straggling thread finishes its computation after 0.643 seconds. In the modified version this thread already finishes after 0.543 seconds. This is a speedup of roughly 1.185. The load-balance efficiency in the modified version is also improved and is now at 89%.
