Performance Optimisation and Productivity
For loops full auto-vectorization
Similar to the For loops poor auto-vectorization experiment, here we will highlight a set of metrics that can be used to understand the efficiency of a program when using vector instructions (metrics are provided by Extrae version 3.8.3 and displayed by Paraver 4.9.0). Furthermore, we are conducting the same exact setup, so the reader can compare both experiments to clearly understand the impact in performance (especially in the matrix multiplication example)
Setup for this experiment:
- Vector addition kernel: Arrays of size 134 million elements;
- Matrix multiplication kernel: Square matrices of 2048 by 2048 elements;
Performance metrics for this experiment (*):
- AVL - Average Vector Length: This metric represents the ration between the number of double-precision floating-point operations and the number of double-precision floating-point vector instructions.
- OPC - Operations per cycle: This metric describes the ratio between the number of double-precision floating-point operations and the total number of useful cycles.
The first step is to examine the verbose provided by the compiler. To know more about this topic, we refer the reader the reader to the For loops full auto-vectorization version.
Setup for this experiment:
- Vector addition kernel: Arrays of size 134 million elements;
- Matrix multiplication kernel: Square matrices of 8192 by 8192 elements;
Vector Addition
Compiler report:
Begin optimization report for: vadd_v2(double *, double *, double *, int)
Report from: Vector optimizations [vec]
LOOP BEGIN at /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/vadd_v2.c(5,2)
remark #15388: vectorization support: reference c[i] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/vadd_v2.c(5,25) ]
remark #15388: vectorization support: reference a[i] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/vadd_v2.c(5,30) ]
remark #15388: vectorization support: reference b[i] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/vadd_v2.c(5,35) ]
remark #15305: vectorization support: vector length 8
remark #15300: LOOP WAS VECTORIZED
remark #15448: unmasked aligned unit stride loads: 2
remark #15449: unmasked aligned unit stride stores: 1
remark #15475: --- begin vector cost summary ---
remark #15476: scalar cost: 8
remark #15477: vector cost: 0.620
remark #15478: estimated potential speedup: 12.300
remark #15488: --- end vector cost summary ---
LOOP END
LOOP BEGIN at /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/vadd_v2.c(5,2)
<Remainder loop for vectorization>
remark #15388: vectorization support: reference c[i] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/vadd_v2.c(5,25) ]
remark #15388: vectorization support: reference a[i] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/vadd_v2.c(5,30) ]
remark #15388: vectorization support: reference b[i] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/vadd_v2.c(5,35) ]
remark #15305: vectorization support: vector length 8
remark #15309: vectorization support: normalized vectorization overhead 0.857
remark #15301: REMAINDER LOOP WAS VECTORIZED
LOOP END
===========================================================================
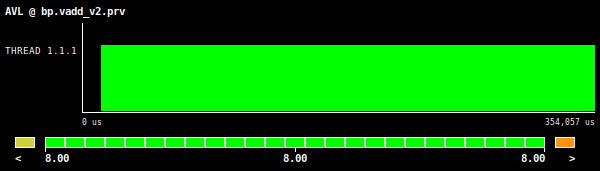 Figure 1: Vector addition AVL value, using an array size of 134 million elements.
Figure 1: Vector addition AVL value, using an array size of 134 million elements.
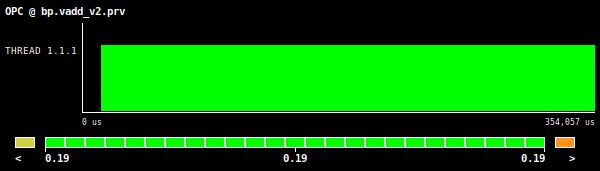 Figure 2: Vector addition OPC value, using an array size of 134 million elements.
Figure 2: Vector addition OPC value, using an array size of 134 million elements.
The information provided by the compiler give us a clear message regarding the vector instructions efficiency. We have here a vector length of 8 and just a remainder loop fully vectorized and with aligned accesses to the required data. This is also translated to the metrics shown in Figures 1 and 2. Specifically we have an AVL value of 8 and an OPC of 0.19.
Matrix multiplication
Compiler report:
Begin optimization report for: matmul_v3(const double *, const double *, double *, const int, const int, const int)
Report from: Vector optimizations [vec]
LOOP BEGIN at /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(5,2)
remark #15542: loop was not vectorized: inner loop was already vectorized
LOOP BEGIN at /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(6,3)
remark #15542: loop was not vectorized: inner loop was already vectorized
LOOP BEGIN at /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(8,4)
remark #15388: vectorization support: reference C[i*N+j] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(8,25) ]
remark #15388: vectorization support: reference C[i*N+j] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(8,25) ]
remark #15388: vectorization support: reference B[k*N+j] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(8,44) ]
remark #15305: vectorization support: vector length 8
remark #15309: vectorization support: normalized vectorization overhead 0.143
remark #15300: LOOP WAS VECTORIZED
remark #15448: unmasked aligned unit stride loads: 2
remark #15449: unmasked aligned unit stride stores: 1
remark #15475: --- begin vector cost summary ---
remark #15476: scalar cost: 11
remark #15477: vector cost: 0.870
remark #15478: estimated potential speedup: 12.040
remark #15488: --- end vector cost summary ---
LOOP END
LOOP BEGIN at /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(8,4)
<Remainder loop for vectorization>
remark #15388: vectorization support: reference C[i*N+j] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(8,25) ]
remark #15388: vectorization support: reference C[i*N+j] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(8,25) ]
remark #15388: vectorization support: reference B[k*N+j] has aligned access [ /gpfs/home/bsc33/bsc33172/POP/auto-vectorization/for-loops-full-auto-vec/src/matmul_v3.c(8,44) ]
remark #15305: vectorization support: vector length 8
remark #15309: vectorization support: normalized vectorization overhead 0.722
remark #15301: REMAINDER LOOP WAS VECTORIZED
LOOP END
LOOP END
LOOP END
===========================================================================
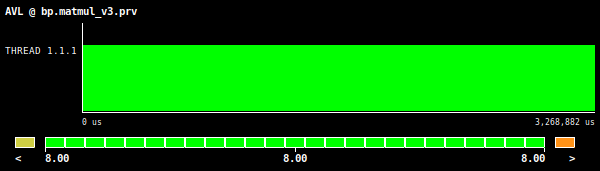 Figure 3: Matrix multiplication AVL value, using square matrices of 2048 by 2048 elements.
Figure 3: Matrix multiplication AVL value, using square matrices of 2048 by 2048 elements.
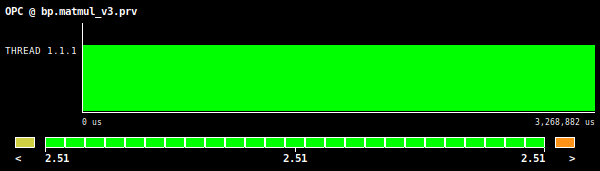 Figure 4: Matrix multiplication OPC value, using square matrices of 2048 by 2048 elements.
Figure 4: Matrix multiplication OPC value, using square matrices of 2048 by 2048 elements.
Starting with the AVL value (Figure 3), we can clearly see that we are using the available vector capabilities of the architecture as this value reads 8 and this is the theoretical vector length of the tested machine (Intel AVX512 ISA). Moreover, if we inspect the OPC value shown in Figure 4 (which spells out 2.51) and compare it with the value given by the For loops poor auto-vectorization experiment, we can detect an improvement of 10x.
(*) These performance metrics are being developed by MEEP and POP2 projects.
