Performance Optimisation and Productivity
Very fine-grained tasks/chunks
Usual symptom(s):- Communication Efficiency: The Communication Efficiency (CommE) is the maximum, across all processes, of the ratio between Useful Computation Time and Total Runtime. (more...)
The essential purpose of parallel programming is to reduce the runtime by dividing time-demanding computations among available resources. The granularity is an important aspect that is often overlooked. The amount of work assigned to a computational core/thread has to have a reasonable size so that the overhead caused by thread/core control does not degrade the performance. When the tasks or chunks are too small, this overhead can cost the same or even more time than the computation itself. In such a case, running a program in parallel may not bring any benefit or even can consume more time and resources than running as a single thread application.
As the OpenMP is the most commonly used library providing shared-memory parallelism, we present a silver code using the OpenMP constructs. A programmer aims to accelerate the for loop containing a simple operation by utilizing cores available within a single node. A general form of threaded for-loop with the large_number of iterations distributed chunk-wise among num_threads threads with particular chunks being of the size of chunk_size reads as follows.
// within an OpenMP parallel region with num_treads
#pragma omp for schedule( dynamic, chunk_size )
for(int i=0; i < large_number; i++){
// simple operation with no dependency
do_simple_operation();
}
The most OpenMP overhead comes from the scheduling of the threads. When using the dynamic scheduler, each thread executes a chunk of iterations and then requests another chunk until none remains. The runtime does a thread control after each chunk of iterations is computed.
When the runtime of the do_simple_operation() is low - in the order of nanoseconds, and the chunk_size is small - units or tens, then the for-loop may perform poorly. The common pitfall is to omit the chunk_size in the schedule(dynamic) construct. In such a case, the default value is applied, which is one. In some cases, an unfamiliar programmer may choose number one as he has not enough experience. Nevertheless, this value may not be optimal for the described test case.
The silver code above may be equivalently written using tasks. The chunk_size parameter specifies the size of each task, and a large_number/chunk_size determines their number.
For nowadays multi-core architectures, we may expect to have the number of cores approximately in a range from 4 to 50. Therefore, we typically run applications with num_threads <= 50.
Example
In the following example, we can see the effect of having 1 iteration in a chunk with this chunk’s granularity around 1-3 us. The total number of iterations is 27920. This number is distributed among 6 threads, and thus each tread performs around 4600 chunks (iterations).
In the figure, we can see a timeline with the ‘state view’ for one MPI process with 6 OpenMP threads within the BEM4I application. Instead of being on the running state, all threads spend a lot of time in the Scheduling and Fork/Join state related to the OpenMP overhead. The granularity of the yellow and blue parts is similar (1-3 us) except for some noise that is not important here.
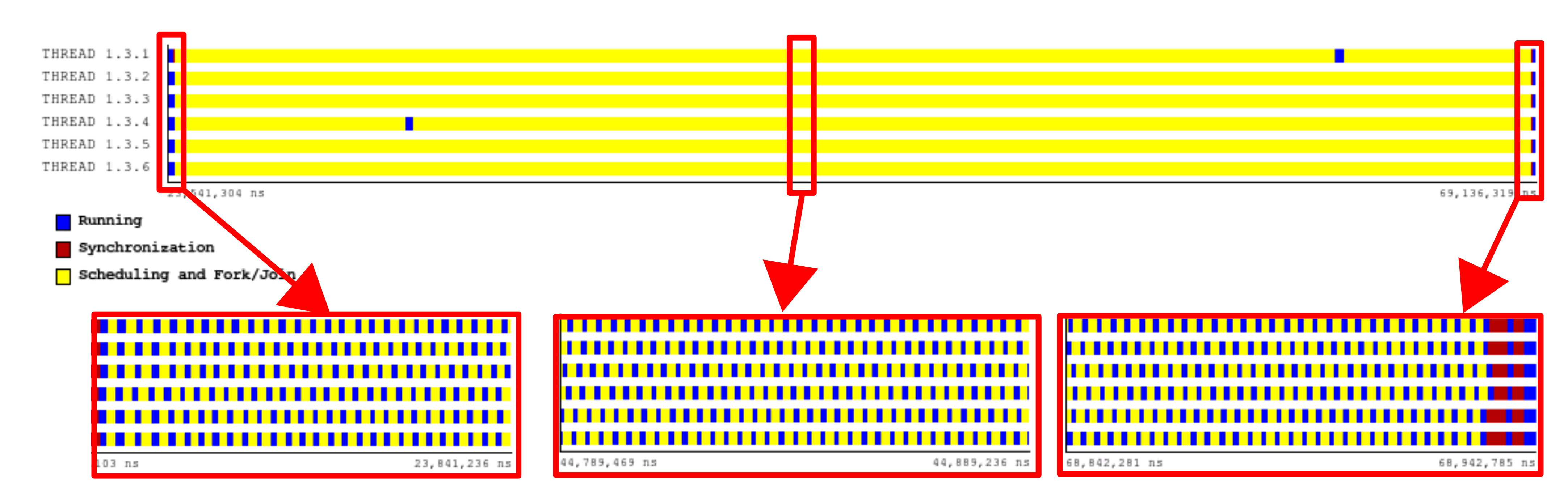
The total runtime of this loop is 14.06 ms (14060 us). The Load balance is 98%, while the Communication efficiency is only 51%. Their multiplication makes the Parallel efficiency 50%. (Additionally, the average useful IPC is 0.86.)
| Parallel eff. | 0.50 |
|---|---|
| - Load Balance | 0.98 |
| - Communication eff. | 0.51 |
| Other statistics | |
|---|---|
| Runtime | 14 ms |
| IPC | 0.86 |
| # Instructions | 104422220 |
| Frequency | 2.86 GHz |
- A large number of iterations - number of iteration is significantly larger (many times) than the number of threads. ⇒ Chunk/task grain-size trade-off (parallelism/overhead)
